ethanhe42/channel-pruning
Shrink CNNs by cutting entire channels, not random weights
An ICCV 2017 method that speeds up deep networks by pruning whole feature-map channels and recovering accuracy with a custom Caffe fork.
Not currently ranked — collecting fresh signals.
star history
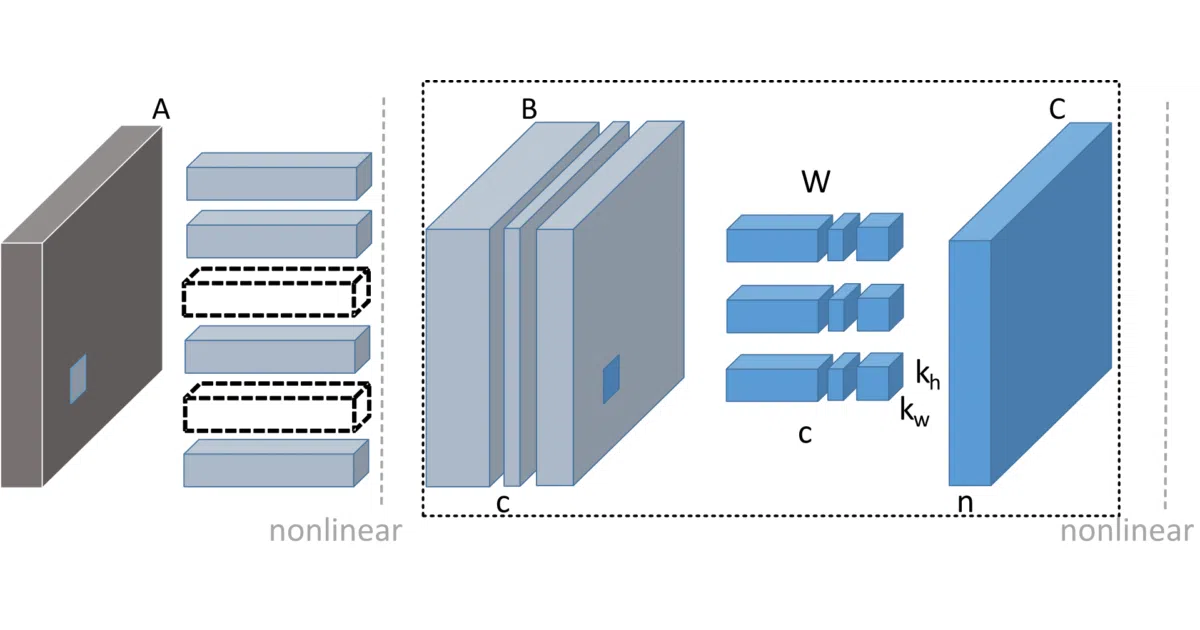
What it does This repo implements channel pruning: instead of zeroing out individual weights (which hardware mostly ignores), it removes entire channels from convolution layers, then finetunes to recover accuracy. It targets old-school Caffe models—VGG-16, ResNet-50, even Faster R-CNN—with published speed-ups of 2×–5× and pre-pruned model weights ready to download.
The interesting bit The “3C” method fuses two older techniques—spatial low-rank decomposition plus channel decomposition—into a single pipeline. The author also maintains a patched Caffe fork with bicubic interpolation and a specific 256-then-crop preprocessing, so you are locked into their toolchain end-to-end.
Key highlights
- Pre-built pruned models available for 4× VGG-16, 2× ResNet-50, and 2×/4× Faster R-CNN
- Top-1 accuracy drops modestly: VGG-16 goes from ~71.5% to 70.6% at 4× speed, or 67.8% at 5×
- Requires 4 GPUs (~11 GB each) for finetuning at batch size 128
- Python 3 scaffolding around a Caffe C++ core; dependencies include scipy, sklearn, easydict
- Paper authors later evolved this into AMC (ECCV 2018), which swaps manual pruning for reinforcement learning
Caveats
- Hard dependency on the author’s Caffe fork; not PyTorch or TensorFlow
- Setup is involved: clone recursive, build Caffe from source, download ImageNet, hand-edit prototxt paths
- README contains a broken “next section” link and some mangled step numbering
Verdict Worth a look if you are maintaining legacy Caffe pipelines or studying structured pruning fundamentals. Everyone else should probably jump straight to the authors’ later AMC work or modern PyTorch pruning toolkits.
Frequently asked
- What is ethanhe42/channel-pruning?
- An ICCV 2017 method that speeds up deep networks by pruning whole feature-map channels and recovering accuracy with a custom Caffe fork.
- Is channel-pruning open source?
- Yes — ethanhe42/channel-pruning is open source, released under the MIT license.
- What language is channel-pruning written in?
- ethanhe42/channel-pruning is primarily written in Python.
- How popular is channel-pruning?
- ethanhe42/channel-pruning has 1.1k stars on GitHub.
- Where can I find channel-pruning?
- ethanhe42/channel-pruning is on GitHub at https://github.com/ethanhe42/channel-pruning.