enazoe/yolo-tensorrt
A C++ wrapper that drags YOLO into TensorRT
Encapsulates NVIDIA's reference code so you can run YOLOv3 through v5 on GPUs and Jetson boards without wrestling the plumbing yourself.
Not currently ranked — collecting fresh signals.
star history
What it does
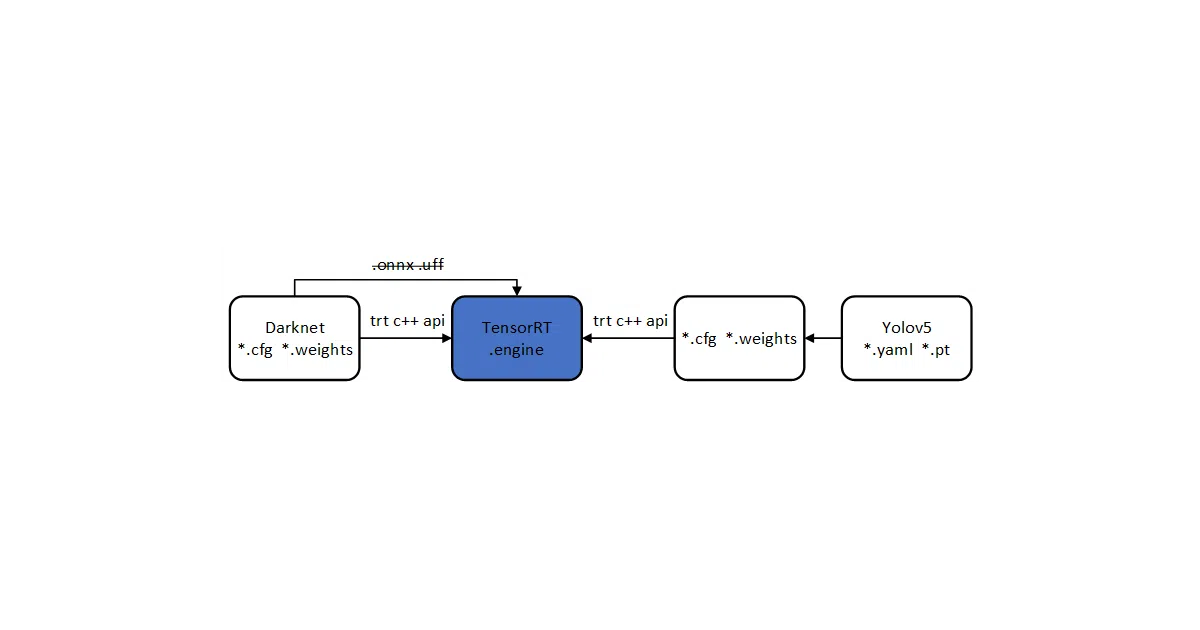
This repo wraps NVIDIA’s official yolo-tensorrt implementation into a reusable C++ library. Feed it darknet .weights and .cfg files for YOLOv3 or v4, or PyTorch .pt and .yaml for YOLOv5, and it spits out a compiled TensorRT engine. The API is deliberately thin: configure, init, then detect() on a vector of OpenCV mats.
The interesting bit
The value isn’t the engine — it’s the packaging. NVIDIA’s reference code is a starting point; this turns it into a Windows DLL or Linux .so you can actually ship. It also carries benchmark tables across x86, Titan V, and Jetson NX, so you can eyeball the INT8 vs FP16 vs FP32 trade-offs before you build.
Key highlights
- Supports YOLOv3, v4, and v5 (n/s/m/l/x, plus v5-p6) with raw darknet or PyTorch weights
- Batch inference and unequal width/height inputs work out of the box
- Precision modes: FP32, FP16, INT8 (with calibration image list for INT8)
- Builds on Windows 10 (VS2015), Ubuntu 18.04, and L4T/Jetson
- Ships as
libdetector.so/ DLL with a minimal C++ API and a sample CMake for external projects
Caveats
- Dynamic input size is listed as not yet supported
- Dependencies are pinned fairly tightly: TensorRT 7.1.3.4, CUDA 11.0, cuDNN 8.0, OpenCV4
- FP16 benchmarks are sparse or missing on some GPU rows in the tables
Verdict
Grab this if you need YOLO running fast on Jetson or desktop and don’t want to hand-roll the TensorRT conversion. Skip it if you need dynamic input sizes or are allergic to pinned dependency versions.
Frequently asked
- What is enazoe/yolo-tensorrt?
- Encapsulates NVIDIA's reference code so you can run YOLOv3 through v5 on GPUs and Jetson boards without wrestling the plumbing yourself.
- Is yolo-tensorrt open source?
- Yes — enazoe/yolo-tensorrt is open source, released under the MIT license.
- What language is yolo-tensorrt written in?
- enazoe/yolo-tensorrt is primarily written in C++.
- How popular is yolo-tensorrt?
- enazoe/yolo-tensorrt has 1.2k stars on GitHub.
- Where can I find yolo-tensorrt?
- enazoe/yolo-tensorrt is on GitHub at https://github.com/enazoe/yolo-tensorrt.