dylanhogg/llmgraph
Wikipedia + LLM = crowdsourced ontology, minus the crowd
A CLI tool that turns any Wikipedia page into a structured knowledge graph by recursively asking an LLM "what else is like this?"
Not currently ranked — collecting fresh signals.
star history
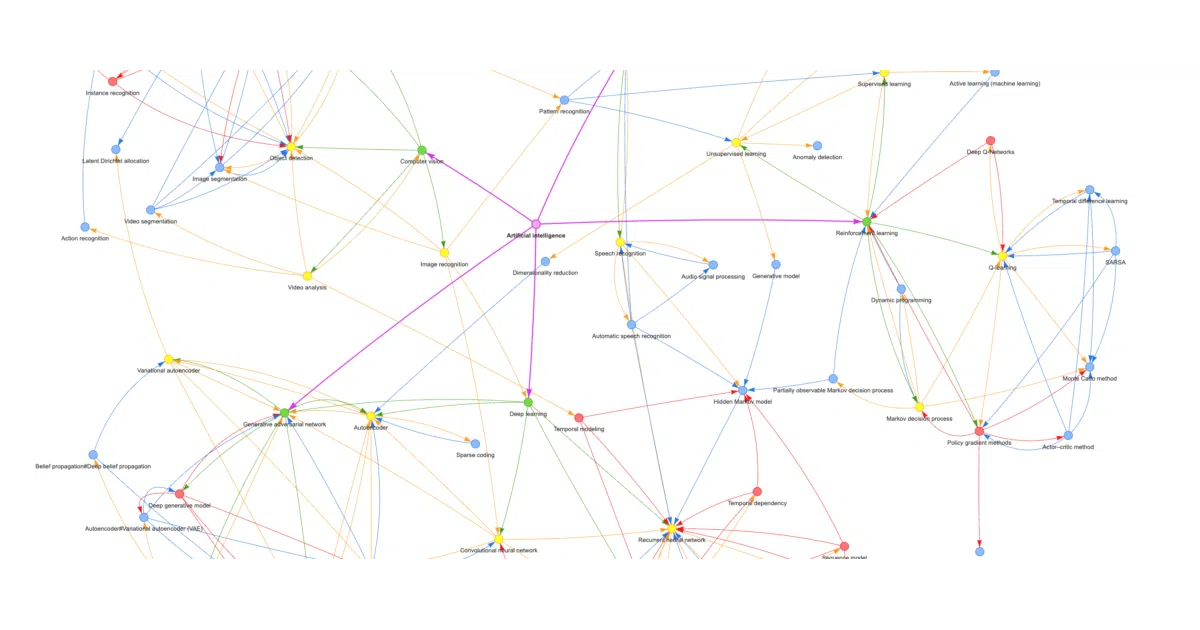
What it does
llmgraph takes a Wikipedia URL and an entity type (movie, software-engineering, food, etc.), then prompts an LLM to find related entities with similarity scores and reasons. It repeats this recursively to build a multi-level graph, deduplicating nodes along the way. Output is GraphML, GEXF, or an interactive HTML visualization via pyvis.
The interesting bit
The prompts are the product. Each entity type gets a handcrafted persona—“You are a highly knowledgeable ontologist” for concepts, “You are knowledgeable about documentaries” for films—which shapes how the LLM reasons about similarity. The project also surfaces total token counts, making the ~1¢ cost of a default run explicit rather than hidden.
Key highlights
- 15 built-in entity types with tailored prompts in a single YAML file
- Caches LLM and Wikipedia calls so you can iteratively deepen graphs without re-spending tokens
- Swappable models via LiteLLM, including local Ollama instances (though prompts were tuned for OpenAI)
- Outputs token usage for cost transparency; default gpt-5-mini run is under 2 cents
- Includes a ready-to-run Colab notebook
Caveats
- Prompts are optimized for OpenAI; the README notes Llama2 results are “ok, but not as good”
- Requires Wikipedia as the root source; removing this dependency is listed as future work
- Temperature is locked to 1.0 for gpt-5 models, which may limit reproducibility tuning
Verdict
Worth a spin if you need quick, explorable concept maps for research or prototyping. Skip it if you need rigorous, ground-truth-validated ontologies—the LLM’s “world knowledge” is only as reliable as the model’s training data and the prompt’s framing.
Frequently asked
- What is dylanhogg/llmgraph?
- A CLI tool that turns any Wikipedia page into a structured knowledge graph by recursively asking an LLM "what else is like this?"
- Is llmgraph open source?
- Yes — dylanhogg/llmgraph is open source, released under the MIT license.
- What language is llmgraph written in?
- dylanhogg/llmgraph is primarily written in Jupyter Notebook.
- How popular is llmgraph?
- dylanhogg/llmgraph has 508 stars on GitHub.
- Where can I find llmgraph?
- dylanhogg/llmgraph is on GitHub at https://github.com/dylanhogg/llmgraph.