dongjun-Lee/text-classification-models-tf
Six ways to classify text, circa 2018 TensorFlow
A clean reference zoo of CNN, RNN, and attention architectures for text classification, all trained on DBpedia with one command.
Not currently ranked — collecting fresh signals.
star history
What it does
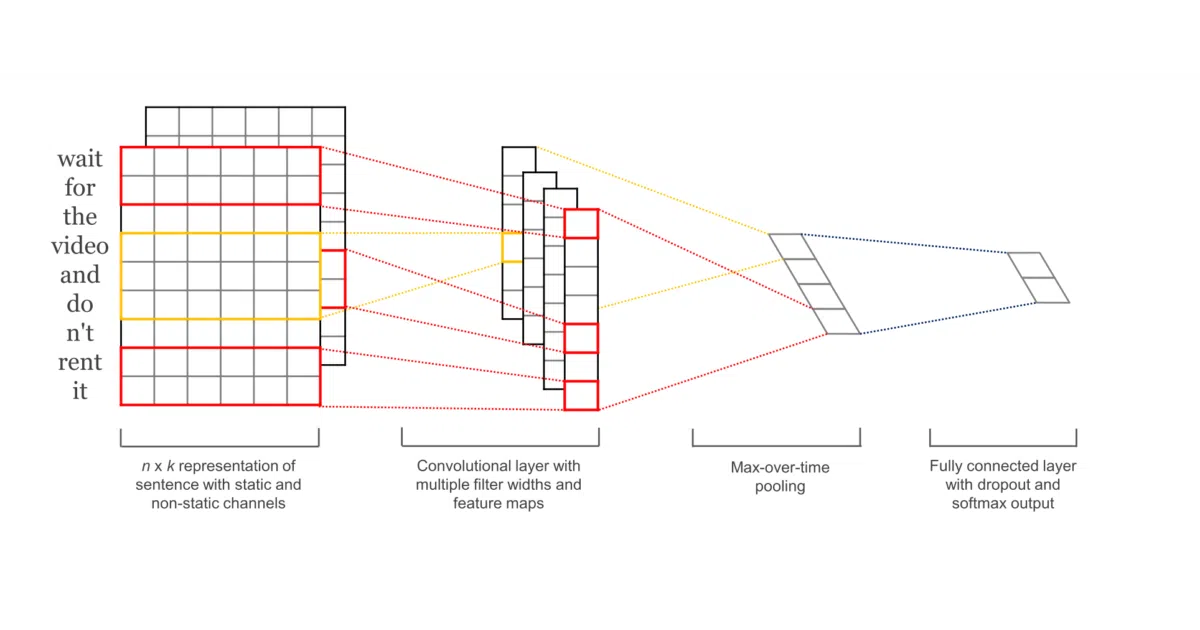
This repo implements six classic text classification architectures in TensorFlow 1.x: word-level CNN, character-level CNN, very deep CNN, bidirectional RNN, attention-based bidirectional RNN, and RCNN. Each model is a standalone script you train with python train.py --model="<name>" and test with python test.py. The included DBpedia dataset means you can reproduce results immediately without hunting for data.
The interesting bit
The value is in the side-by-side comparison: every model is evaluated on the same dataset, with accuracies clustering tightly between 97.6% and 98.7%. That near-parity across wildly different architectures—convolutional vs. recurrent, word vs. character—is itself a useful lesson in diminishing returns.
Key highlights
- Six architectures with direct paper links: Kim 2014, Zhang et al. 2015, Conneau et al. 2016, and others
- One-liner training via
--modelflag:word_cnn,char_cnn,vd_cnn,word_rnn,att_rnn,rcnn - Reproducible DBpedia benchmark table included; best reported result is RCNN at 98.68%
- Semi-supervised variants (SA-LSTM, LM-LSTM) live in a separate linked repo
- Architecture diagrams embedded directly in README for quick mental parsing
Caveats
- TensorFlow 1.x era code; no mention of TF 2.x, Keras, or modern
tf.datapipelines - No pretrained weights provided—you train from scratch every time
- README is sparse on hyperparameters, dataset preprocessing details, or training time
Verdict
Grab this if you need clean, minimal reference implementations to compare how 2014–2016 text classification papers actually behave on identical data. Skip it if you want production-ready code, modern TensorFlow, or explanations of why one architecture might win over another beyond the raw accuracy numbers.
Frequently asked
- What is dongjun-Lee/text-classification-models-tf?
- A clean reference zoo of CNN, RNN, and attention architectures for text classification, all trained on DBpedia with one command.
- Is text-classification-models-tf open source?
- Yes — dongjun-Lee/text-classification-models-tf is an open-source project tracked on heatdrop.
- What language is text-classification-models-tf written in?
- dongjun-Lee/text-classification-models-tf is primarily written in Python.
- How popular is text-classification-models-tf?
- dongjun-Lee/text-classification-models-tf has 503 stars on GitHub.
- Where can I find text-classification-models-tf?
- dongjun-Lee/text-classification-models-tf is on GitHub at https://github.com/dongjun-Lee/text-classification-models-tf.