different-ai/embedbase
Vector search without the infrastructure tantrum
A hosted API that wraps LLMs and vector databases so you don't have to babysit either.
Not currently ranked — collecting fresh signals.
star history
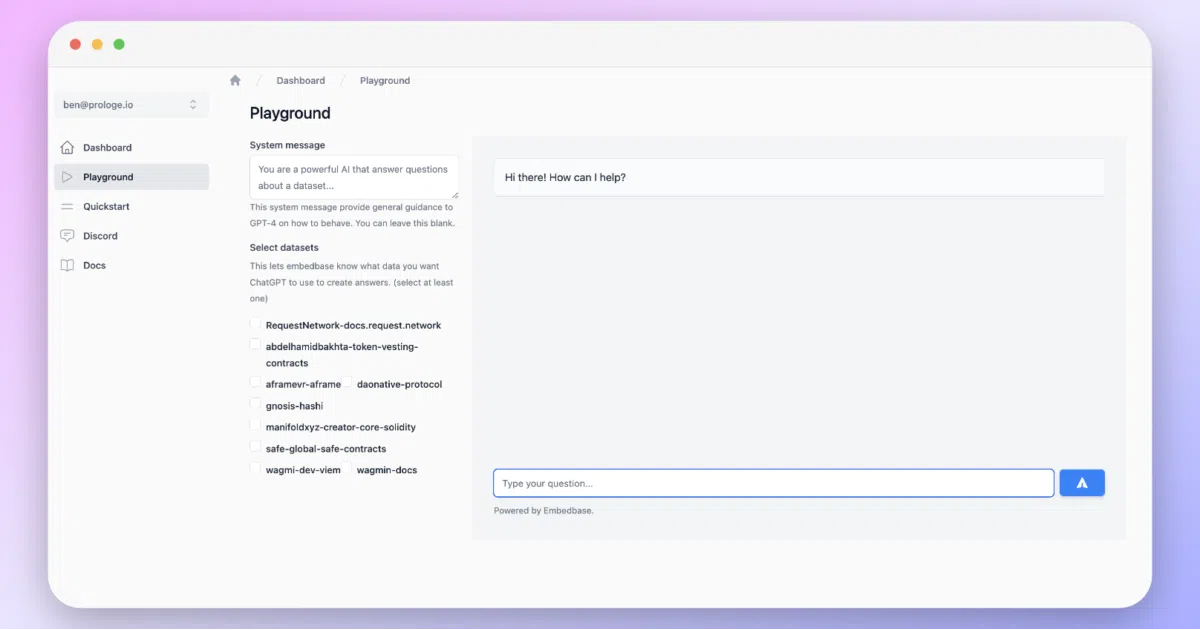
What it does Embedbase is a hosted API that lets you store text in a vector database and query it semantically, then pipe results into text generation from 9+ LLMs. You sign up, get an API key, and skip the part where you wrestle with pgvector deployments or embedding models.
The interesting bit
The whole pitch is “dead-simple” — and the README actually means it. The JavaScript SDK is three methods: .add() to ingest, .search() to retrieve, .generateText() to complete. No mention of chunking strategies, index tuning, or model quantization. That either means the complexity is well-hidden or punted to the hosted side.
Key highlights
- Hosted embeddings-as-a-service; no self-hosted vector DB required
- JavaScript SDK with
.dataset(),.search(),.useModel(),.generateText()chain - Claims 9+ LLM backends (specific models not listed beyond
openai/gpt-3.5-turbo) - Used in production by at least two external projects: AVA (Obsidian plugin) and Solpilot (smart contract chat)
- Documentation itself is “powered by GPT-4” with direct Q&A
Caveats
- The README is thin on architecture details: unclear how embeddings are generated, what vector backend runs under the hood, or pricing structure
- “9+ LLMs” is stated without enumeration; only OpenAI model explicitly shown in examples
- Self-hosting option not mentioned — appears to be hosted-only
Verdict Good fit if you need semantic search + LLM generation yesterday and would rather pay than configure. Skip if you need fine-grained control over embedding models, chunking, or require on-premise deployment.
Frequently asked
- What is different-ai/embedbase?
- A hosted API that wraps LLMs and vector databases so you don't have to babysit either.
- Is embedbase open source?
- Yes — different-ai/embedbase is open source, released under the MIT license.
- What language is embedbase written in?
- different-ai/embedbase is primarily written in TypeScript.
- How popular is embedbase?
- different-ai/embedbase has 524 stars on GitHub.
- Where can I find embedbase?
- different-ai/embedbase is on GitHub at https://github.com/different-ai/embedbase.