dhwajraj/deep-siamese-text-similarity
A twin-LSTM network that spots "IBM" hiding inside "International Business Machines"
Prototype siamese network learns both character-level phrase matching and word-level sentence similarity through shared LSTM encoders.
Not currently ranked — collecting fresh signals.
star history
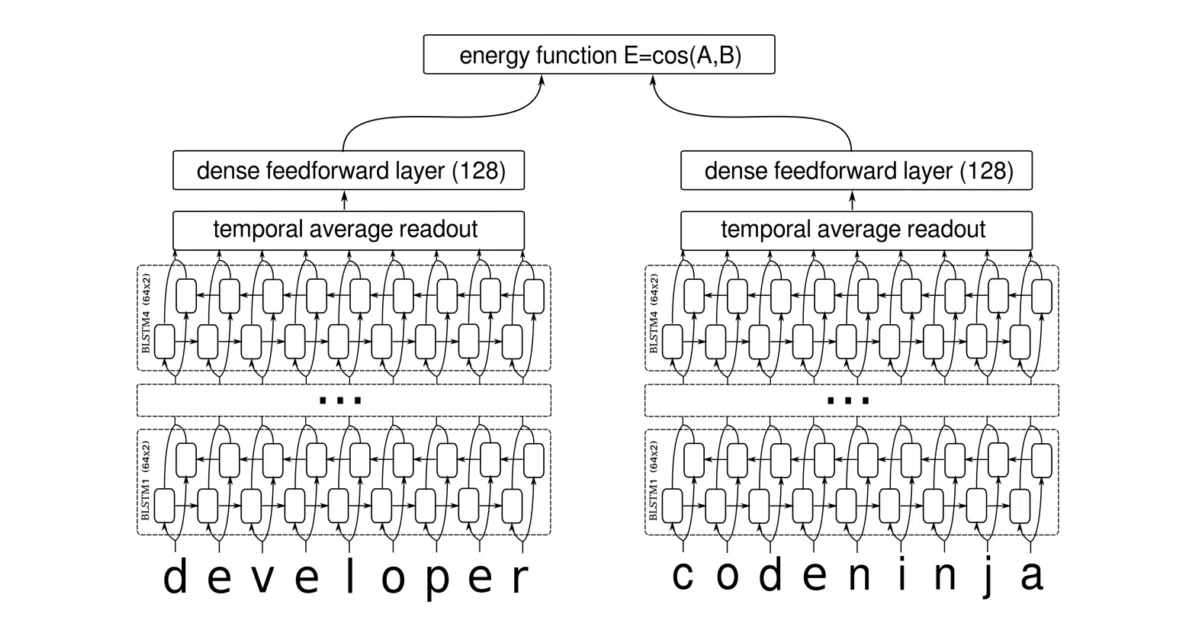
What it does
This repo implements a siamese LSTM network in TensorFlow that learns to score how similar two text strings are. It handles two distinct jobs: matching short phrases by character (so “J.B.D. Joshi” and “James Joshi” read as the same person) and scoring sentence semantics by word (so “He is smart” and “He is a wise man” cluster together). Both modes feed paired inputs through twin LSTMs and train with Euclidean-distance contrastive loss.
The interesting bit
The same architecture toggles between character and word embeddings with a single flag. The phrase mode is the less common trick: it learns structural similarity—abbreviations, typos, extra punctuation—without any dictionary, just by grinding on character sequences. The README’s person-name examples are a nice touch of real-world messiness.
Key highlights
- Character-level phrase mode: 91% accuracy on person-name disambiguation, ~7 min/epoch on 8-core CPU
- Word-level sentence mode: 81% accuracy on semantic pairs, ~8 min/epoch, uses pre-trained embeddings (tested with fastText)
- Contrastive loss with explicit “similar / not similar” training pairs; can learn directionality (“Microsoft buys LinkedIn” ≠ “LinkedIn buys Microsoft”)
- Supports arbitrary pre-trained word2vec/fastText vectors via text/bin/text.gz formats
- Ships with sample training data and Google Drive links for full phrase and SNLI-derived sentence corpora
Caveats
- Explicitly labeled prototype / not production-grade by the author
- Pinned to TensorFlow 1.2.1, numpy 1.11.0, gensim 1.0.1—deeply legacy stack in 2024
- Training data lives on external Google Drive links; no guarantees of availability
Verdict
Worth a read if you’re studying siamese architectures or need a baseline for entity matching with noisy short strings. Skip it if you want a maintained, production-ready similarity model—this is a 2016-era research prototype frozen in time.
Frequently asked
- What is dhwajraj/deep-siamese-text-similarity?
- Prototype siamese network learns both character-level phrase matching and word-level sentence similarity through shared LSTM encoders.
- Is deep-siamese-text-similarity open source?
- Yes — dhwajraj/deep-siamese-text-similarity is open source, released under the MIT license.
- What language is deep-siamese-text-similarity written in?
- dhwajraj/deep-siamese-text-similarity is primarily written in Python.
- How popular is deep-siamese-text-similarity?
- dhwajraj/deep-siamese-text-similarity has 1.4k stars on GitHub.
- Where can I find deep-siamese-text-similarity?
- dhwajraj/deep-siamese-text-similarity is on GitHub at https://github.com/dhwajraj/deep-siamese-text-similarity.