denisyarats/pytorch_sac
SAC in PyTorch: clean reimplementation, fixed hyperparameters
A readable PyTorch port of Soft Actor-Critic that benchmarks against D4PG on DM Control Suite without tuning per-task.
Not currently ranked — collecting fresh signals.
star history
What it does
Implements Soft Actor-Critic (SAC), an off-policy reinforcement learning algorithm for continuous control. Trains agents on DeepMind Control Suite tasks like cheetah_run via a single CLI command, then spits out TensorBoard logs and eval videos to an exp folder.
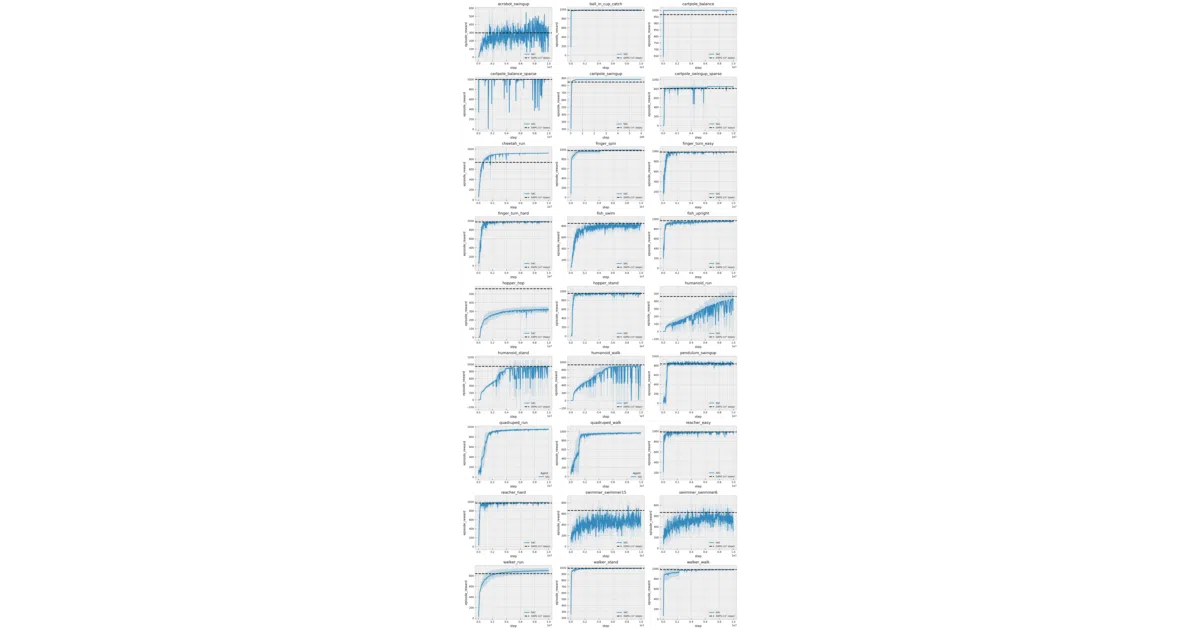
The interesting bit
The authors ran SAC against D4PG across the full DM Control Suite using one fixed hyperparameter set — no per-task tuning, which is where RL code often hides its cheating. They plot p95 confidence intervals over 3 seeds, and the README notes D4PG’s numbers come from the original paper at 10⁸ steps (a frank disclosure, not a gotcha).
Key highlights
- Single-command training:
python train.py env=cheetah_run - Benchmarks on DM Control Suite with consistent hyperparameters across all tasks
- Outputs TensorBoard logs, train/eval metrics, and episode videos automatically
- Requires CUDA 9.2 GPU; dependencies managed via conda environment file
- Citable implementation with a BibTeX entry provided
Caveats
- CUDA 9.2 is dated; modern GPUs may need dependency tweaks
- Only 3 seeds for confidence intervals — fine for a reference impl, not a paper claim
Verdict
Grab this if you need a readable, citable SAC baseline in PyTorch with sensible defaults. Skip if you need distributed training, newer CUDA, or Atari/discrete action spaces — this is DM Control Suite territory only.
Frequently asked
- What is denisyarats/pytorch_sac?
- A readable PyTorch port of Soft Actor-Critic that benchmarks against D4PG on DM Control Suite without tuning per-task.
- Is pytorch_sac open source?
- Yes — denisyarats/pytorch_sac is open source, released under the MIT license.
- What language is pytorch_sac written in?
- denisyarats/pytorch_sac is primarily written in Jupyter Notebook.
- How popular is pytorch_sac?
- denisyarats/pytorch_sac has 599 stars on GitHub.
- Where can I find pytorch_sac?
- denisyarats/pytorch_sac is on GitHub at https://github.com/denisyarats/pytorch_sac.