deepseek-ai/open-infra-index
DeepSeek's garage-sale of production AI infra: take it or fork it
A meta-repo cataloging the actual kernels, file systems, and scheduling tricks that run DeepSeek-V3/R1 in production—not slides, not promises.
Not currently ranked — collecting fresh signals.
star history
What it does
This is DeepSeek’s open infrastructure index: a curated landing page pointing to six production systems they built and battle-tested for training and serving their V3/R1 models. Think of it as a garage sale where everything actually works—FlashMLA for GPU decoding kernels, DeepEP for MoE communication, DeepGEMM for FP8 matrix math, DualPipe/EPLB for parallelism, and 3FS for storage. Each repo is documented, deployed, and (per the README) “no vaporware.”
The interesting bit
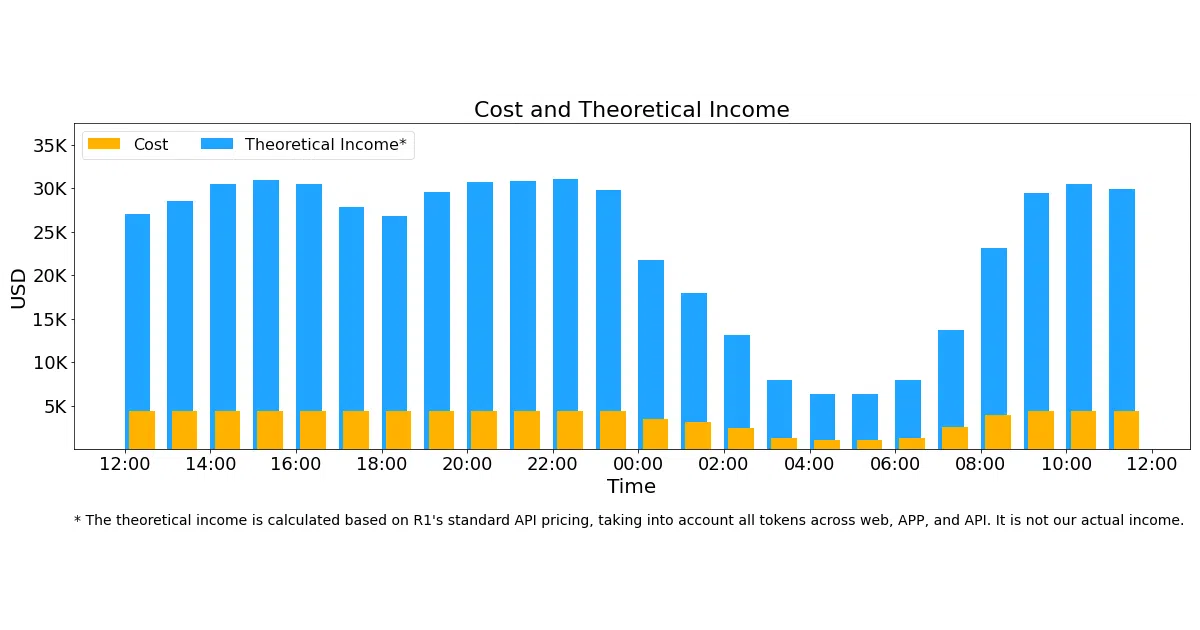
The Day 6 disclosure is unusually blunt: 73.7k input / 14.8k output tokens per second per H800 node, with a claimed 545% cost profit margin. Whether that margin figure is net or gross is unclear, but publishing production economics at all is rare. The 3FS file system hitting 6.6 TiB/s on 180 nodes also suggests they solved the “storage is boring until it isn’t” problem for large-scale training.
Key highlights
- FlashMLA: BF16 MLA decoding kernel, 3000 GB/s memory-bound or 580 TFLOPS compute-bound on H800
- DeepEP: first open-source EP (expert parallelism) communication library for MoE, with NVLink/RDMA intranode and internode
- DeepGEMM: ~300 lines of core logic, JIT-compiled, outperforms expert-tuned kernels on most matrix sizes, 1350+ FP8 TFLOPS
- DualPipe + EPLB + profile-data: bidirectional pipeline parallelism, load balancing, and overlap analysis tools
- 3FS + Smallpond: parallel file system with disaggregated architecture, strong consistency, 40+ GiB/s per client for KVCache lookup
- Papers and ongoing work: ISCA25 hardware reflections, SC24 co-design paper, and a roadmap for open-sourcing the inference engine
Caveats
- The 545% “cost profit margin” lacks definition—gross? net? against what baseline?—so treat it as directional, not audited
- Most repos are separate; this index is glue code and links, not a unified build system
- Hardware assumptions are narrow: Hopper GPUs, heavy reliance on H800-specific optimizations
Verdict
Worth bookmarking if you’re building or operating large MoE training or inference clusters. Skip it if your scale is single-node or your budget doesn’t include RDMA switches and H800s.
Frequently asked
- What is deepseek-ai/open-infra-index?
- A meta-repo cataloging the actual kernels, file systems, and scheduling tricks that run DeepSeek-V3/R1 in production—not slides, not promises.
- Is open-infra-index open source?
- Yes — deepseek-ai/open-infra-index is open source, released under the CC0-1.0 license.
- How popular is open-infra-index?
- deepseek-ai/open-infra-index has 8k stars on GitHub.
- Where can I find open-infra-index?
- deepseek-ai/open-infra-index is on GitHub at https://github.com/deepseek-ai/open-infra-index.