deepseek-ai/Engram
DeepSeek adds a lookup table to LLMs and calls it a sparsity axis
Engram revives N-gram embeddings as O(1) memory retrieval, arguing Transformers need a native knowledge-lookup primitive beyond MoE.
Not currently ranked — collecting fresh signals.
star history
What it does
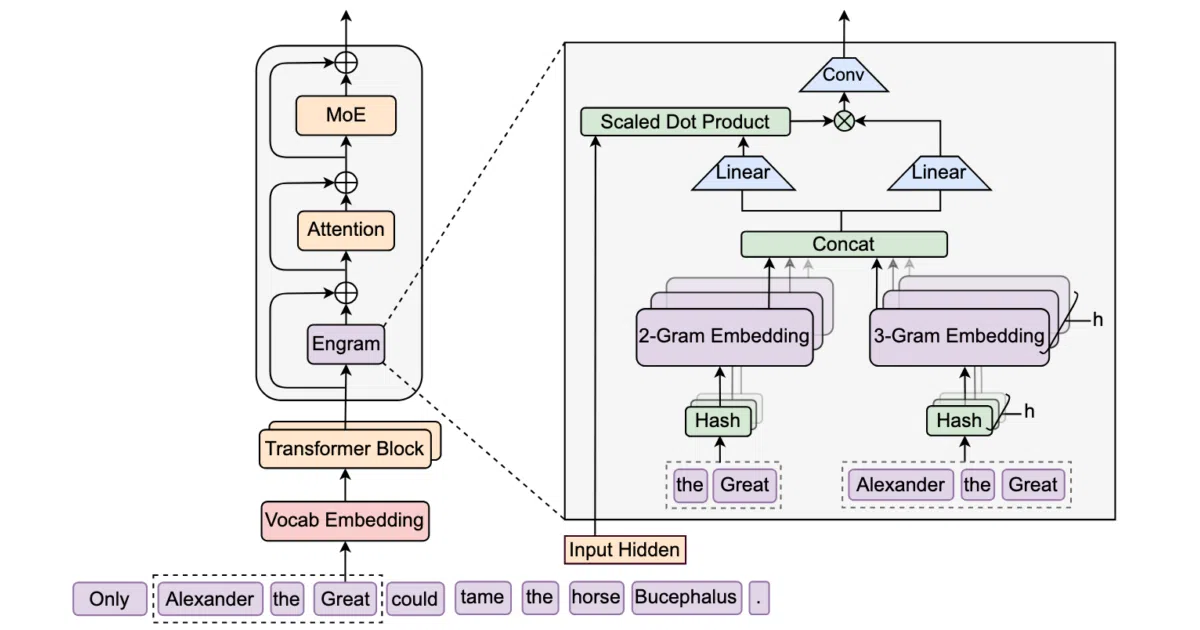
Engram is a module that bolts static N-gram memory retrieval onto a Transformer backbone. It performs deterministic lookups of token-sequence embeddings and fuses them with the model’s dynamic hidden states. The pitch: MoE scales via conditional computation, but Transformers have no native “go look this up” operation, so Engram fills that gap with O(1) addressing.
The interesting bit
The paper identifies a U-shaped scaling law for allocating capacity between neural computation (MoE) and static memory (Engram). The mechanistic claim is that offloading static pattern reconstruction to Engram preserves early-layer capacity for more complex reasoning downstream. Also notable: deterministic addressing lets you park the embedding tables in host memory without torching inference latency.
Key highlights
- Complementary sparsity axis: Positioned as a third knob alongside width and MoE depth for scaling model capacity.
- Iso-param/iso-FLOP wins: Engram-27B reportedly beats MoE baselines on knowledge, reasoning, code, and math under strict budget constraints.
- Host memory offloading: The lookup mechanism is deterministic enough to move massive tables out of GPU memory.
- Standalone demo:
engram_demo_v1.pyruns independently, though it mocks Attention/MoE/mHC to isolate the module.
Caveats
- The repo is a “demonstration version” — core logic only, with standard components stubbed out.
- No training code or pretrained checkpoints are visible in the README; you’ll need to chase the paper or contact DeepSeek for the full stack.
Verdict
Worth a look if you’re researching sparse architectures or memory-augmented LLMs. Skip it if you need production-ready training infrastructure today — this is a research artifact with training wheels still on.
Frequently asked
- What is deepseek-ai/Engram?
- Engram revives N-gram embeddings as O(1) memory retrieval, arguing Transformers need a native knowledge-lookup primitive beyond MoE.
- Is Engram open source?
- Yes — deepseek-ai/Engram is open source, released under the Apache-2.0 license.
- What language is Engram written in?
- deepseek-ai/Engram is primarily written in Python.
- How popular is Engram?
- deepseek-ai/Engram has 4.5k stars on GitHub.
- Where can I find Engram?
- deepseek-ai/Engram is on GitHub at https://github.com/deepseek-ai/Engram.