datalab-to/lift
A 9B model that reads PDFs and fills out JSON schemas
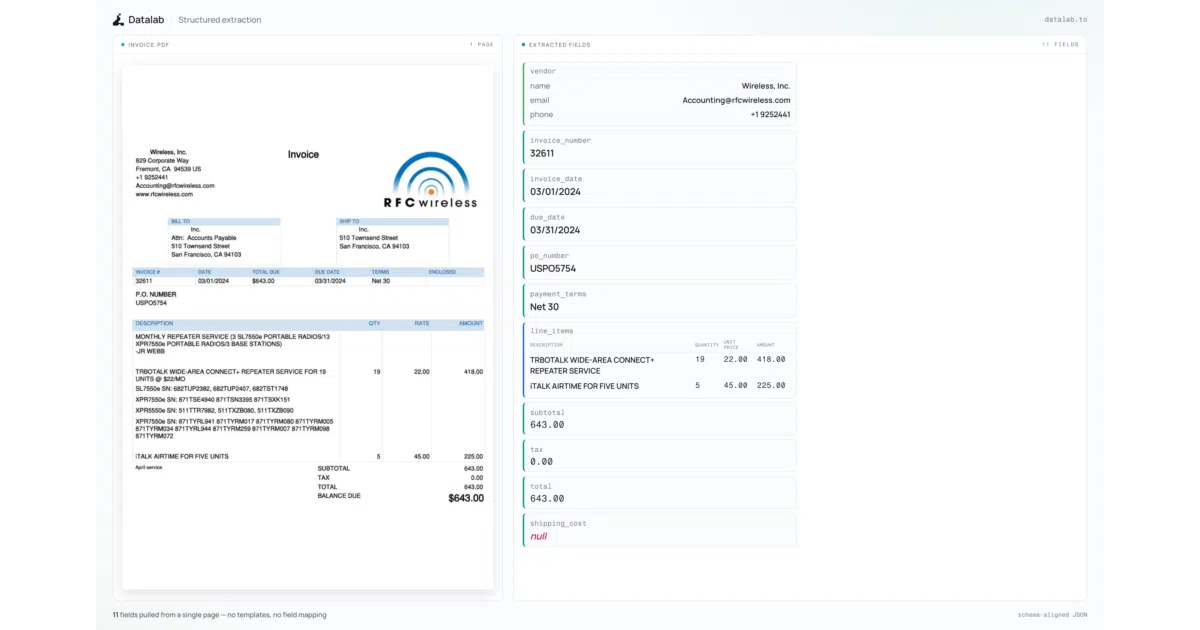
lift extracts structured JSON from PDFs and images by forcing a 9B vision model to follow your schema, preventing hallucinated keys and invalid output.
Collecting fresh signals — velocity needs a few days of history.
collecting data…
star history
What it does
lift is a 9B vision model that ingests PDFs or images and emits structured JSON matching a user-supplied schema. It handles multi-page documents in a single forward pass—even when values span page boundaries—and can run locally via HuggingFace or behind a vLLM server. A bundled Streamlit app, Schema Studio, lets you iteratively design and test schemas against your documents.
The interesting bit
The model uses schema-constrained decoding, which means it literally cannot emit JSON that violates your schema: no phantom fields, no type mismatches. That guarantee weakens if you throw in complex JSON Schema features like enum, $ref, or anyOf, which the decoder skips rather than compiles.
Key highlights
- 90.2% field accuracy on a 225-document adversarial benchmark (6–64 pages each), beating Azure Content Understanding, NuExtract3, and Qwen3.5-9B, though trailing Gemini Flash 3.5 and Datalab’s own hosted API.
- Full-document accuracy is a humbling 20.9%—getting every field right across a long document remains hard even for larger models.
- Weights ship under a modified OpenRAIL-M license: free for research, personal use, and startups under $5M revenue, but using it to compete with Datalab’s API is explicitly prohibited.
- Commercial self-hosting requires a separate license; the hosted Datalab API adds per-field verification, citations, and confidence scores.
Caveats
- Schema-constrained decoding drops guarantees for complex JSON Schema constructs like
enum,$ref, andanyOf; the README warns that the decoder skips schemas it cannot compile. - Full-document exact-match accuracy sits at 20.9%, so expect at least one error per document on longer, adversarial extractions.
- The model weights carry a modified OpenRAIL-M license with an anti-competitive clause and commercial restrictions that may complicate production deployment.
Verdict
Developers who need programmatic document extraction with strict output shapes—and who can tolerate occasional field-level errors—should look here. If you need guaranteed full-document perfection or unfettered commercial redistribution, the hosted API or a different tool is a better fit.
Frequently asked
- What is datalab-to/lift?
- lift extracts structured JSON from PDFs and images by forcing a 9B vision model to follow your schema, preventing hallucinated keys and invalid output.
- Is lift open source?
- Yes — datalab-to/lift is open source, released under the Apache-2.0 license.
- What language is lift written in?
- datalab-to/lift is primarily written in Python.
- How popular is lift?
- datalab-to/lift has 516 stars on GitHub.
- Where can I find lift?
- datalab-to/lift is on GitHub at https://github.com/datalab-to/lift.