da03/Attention-OCR
OCR with a wandering eye: attention maps show where the model looks
A 2016 TensorFlow implementation that teaches a CNN-LSTM to read text by letting it peek at one character at a time.
Not currently ranked — collecting fresh signals.
star history
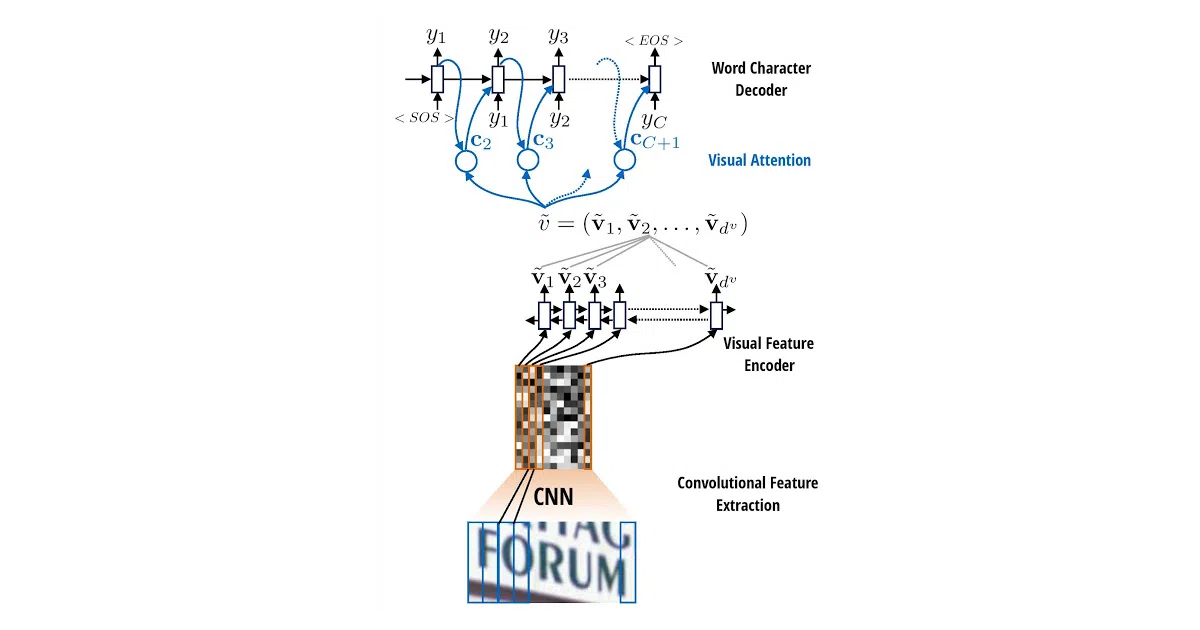
What it does Feed it an image of a word; it resizes to height 32, runs a sliding CNN, stacks an LSTM on top, then uses an attention decoder to emit characters one by one. The output is the predicted text string, plus optional heatmaps showing which slice of the image the model stared at for each letter.
The interesting bit The attention visualization is the payoff: you get per-character attention maps overlaid on the original image, so you can literally watch the model’s eye move left-to-right (or jump around) as it decodes. It’s borrowed from the same Harvard NLP group that turned math images into LaTeX.
Key highlights
- End-to-end trainable: CNN feature extractor + LSTM encoder + attention decoder in one stack
- Ships with a pre-trained model on Synth 90K and evaluation data for ICDAR/IIIT5K/SVT benchmarks
--visualizeflag dumps attention overlays toresults/correctso you can debug misreads- Vocabulary is hardcoded to 39 tokens: digits, lowercase letters, plus padding/GO/EOS
- Built on TensorFlow 0.12.1 with Keras handling the conv layers
Caveats
- TensorFlow 0.12.1 is ancient; expect dependency archaeology to get it running
- Training “takes quite a long time to reach convergence” because the CNN and attention train jointly
- Model structure isn’t saved, only parameters—reconstruct the graph yourself or use their launcher
Verdict Worth a look if you need interpretable OCR or want to understand attention mechanisms in the wild. Skip it if you need production OCR today; modern transformers and cloud APIs have lapped this.
Frequently asked
- What is da03/Attention-OCR?
- A 2016 TensorFlow implementation that teaches a CNN-LSTM to read text by letting it peek at one character at a time.
- Is Attention-OCR open source?
- Yes — da03/Attention-OCR is open source, released under the MIT license.
- What language is Attention-OCR written in?
- da03/Attention-OCR is primarily written in Python.
- How popular is Attention-OCR?
- da03/Attention-OCR has 1.1k stars on GitHub.
- Where can I find Attention-OCR?
- da03/Attention-OCR is on GitHub at https://github.com/da03/Attention-OCR.