clovaai/donut
Document understanding without the OCR baggage
Donut extracts structure from document images using an end-to-end transformer, eliminating the need for external OCR engines.
Not currently ranked — collecting fresh signals.
star history
What it does
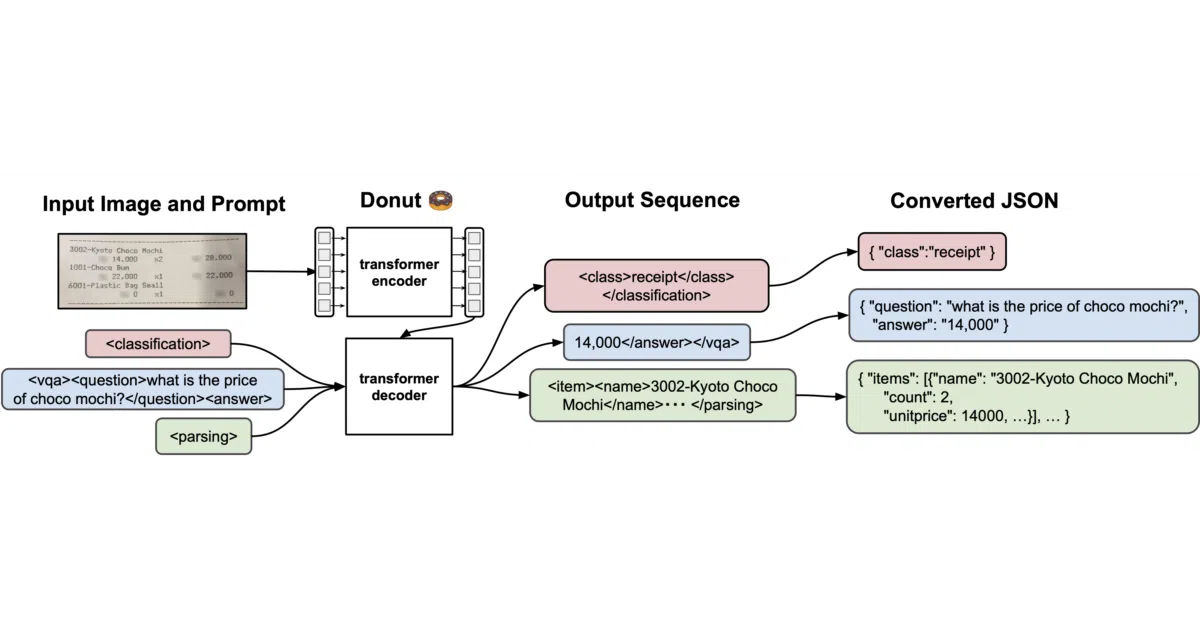
Donut is an OCR-free transformer for document understanding. It ingests images directly and produces structured JSON for tasks like classification, information extraction, and visual question answering. The repo also includes SynthDoG, a synthetic document generator that produces multi-lingual training data to bootstrap models for new languages and domains.
The interesting bit
Rather than piping OCR text into a language model, Donut uses a Swin Transformer encoder to read the page visually and a decoder to generate JSON outputs. Because every task is framed as JSON prediction, the same training pipeline handles receipts, forms, and document VQA with only minor tweaks to the ground-truth format.
Key highlights
- No external OCR engines or APIs required; the model reads raw images end-to-end.
- Unified JSON-prediction pipeline covers classification, parsing, and document VQA.
- SynthDoG generates synthetic documents in English, Chinese, Japanese, and Korean for flexible pre-training.
- Pre-trained checkpoints and interactive Gradio/Colab demos are hosted on Hugging Face.
- The PyPI package
donut-pythonexists, but the README warns of dependency drift with newer library releases.
Caveats
- Local installation is currently temperamental; the authors note that recent updates to core dependencies have broken environments, and they point users to the updated Colab demos as the stable entry point.
Verdict
Worth a look if you want a single model that parses documents visually without orchestrating OCR and NLP pipelines. Look elsewhere if you need something lightweight or friction-free to train from scratch; the hardware bar and dependency drift are real.
Frequently asked
- What is clovaai/donut?
- Donut extracts structure from document images using an end-to-end transformer, eliminating the need for external OCR engines.
- Is donut open source?
- Yes — clovaai/donut is open source, released under the MIT license.
- What language is donut written in?
- clovaai/donut is primarily written in Python.
- How popular is donut?
- clovaai/donut has 6.9k stars on GitHub.
- Where can I find donut?
- clovaai/donut is on GitHub at https://github.com/clovaai/donut.