chris-chris/pysc2-examples
StarCraft II bots that learn by dying repeatedly
A minimal reference implementation for training RL agents on Blizzard's mini-games, back when TensorFlow 1.3 was current.
Not currently ranked — collecting fresh signals.
star history
What it does
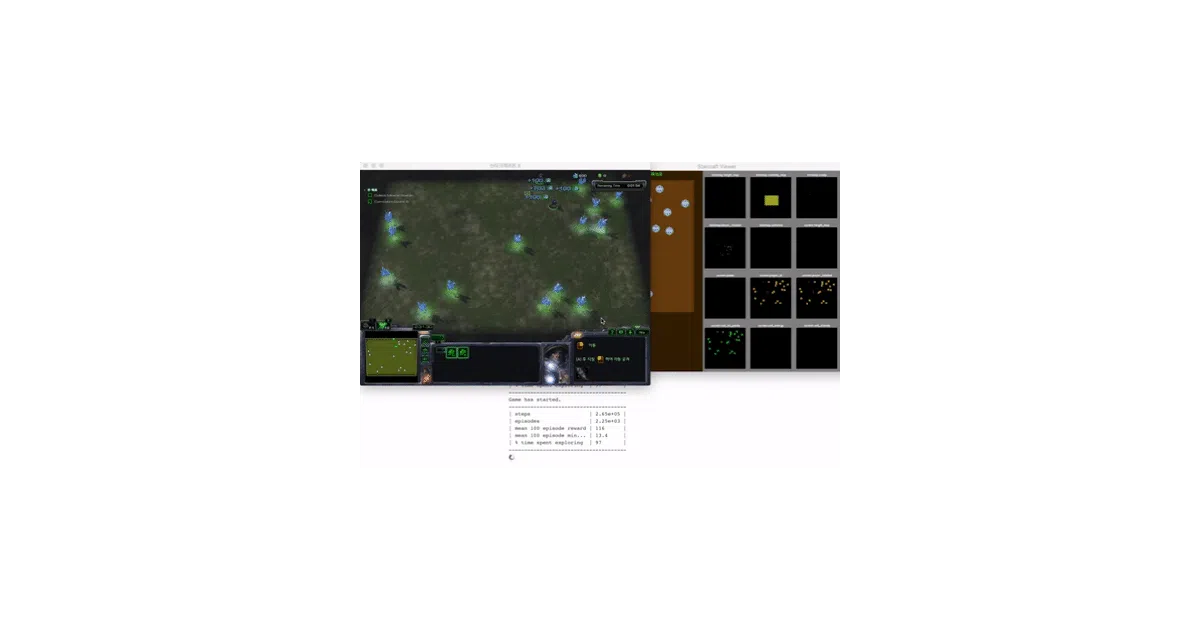
This repo wires DeepMind’s pysc2 environment to OpenAI’s baselines algorithms so you can train agents to play simplified StarCraft II mini-games. The flagship example: a Deep Q-Network that learns to collect mineral shards on a minimap. You get two algorithms (DQN with prioritized replay and dueling networks, plus A2C/A3C) and a handful of tunable hyperparameters.
The interesting bit
The value here is plumbing, not novelty. In 2017, getting three Google-sized dependencies—DeepMind’s environment, OpenAI’s RL library, and Blizzard’s game client—to actually talk to each other was non-trivial. This repo is essentially a working docker-compose.yml for your GPU.
Key highlights
- Supports DQN (with dueling + prioritized replay toggles) and A2C out of the box
- Hyperparameters exposed as CLI flags: learning rate, exploration fraction, agent count, n-step returns
- Includes
enjoy_mineral_shards.pyfor watching your agent stumble around after training - One working GIF of the mineral-shard task, which is more documentation than some repos provide
Caveats
- TensorFlow 1.3 dependency dates this to roughly the Obama administration; expect dependency hell on modern Python
- Only one mini-game (CollectMineralShards) is actually demonstrated
- README numbering jumps from 4 to 5 back to 4-1, suggesting maintenance has been sparse
Verdict
Worth a look if you’re trying to understand how pysc2 and baselines once fit together, or need a historical baseline for SC2 RL research. Skip it if you want maintained, multi-task StarCraft agents—this is a fossil, not a foundation.
Frequently asked
- What is chris-chris/pysc2-examples?
- A minimal reference implementation for training RL agents on Blizzard's mini-games, back when TensorFlow 1.3 was current.
- Is pysc2-examples open source?
- Yes — chris-chris/pysc2-examples is open source, released under the Apache-2.0 license.
- What language is pysc2-examples written in?
- chris-chris/pysc2-examples is primarily written in Python.
- How popular is pysc2-examples?
- chris-chris/pysc2-examples has 756 stars on GitHub.
- Where can I find pysc2-examples?
- chris-chris/pysc2-examples is on GitHub at https://github.com/chris-chris/pysc2-examples.