carpedm20/lstm-char-cnn-tensorflow
A 2016 paper port that never quite finished its homework
TensorFlow reimplementation of Yoon Kim's character-level LSTM language model, stalled with known performance issues and unreproduced benchmarks.
Not currently ranked — collecting fresh signals.
star history
What it does
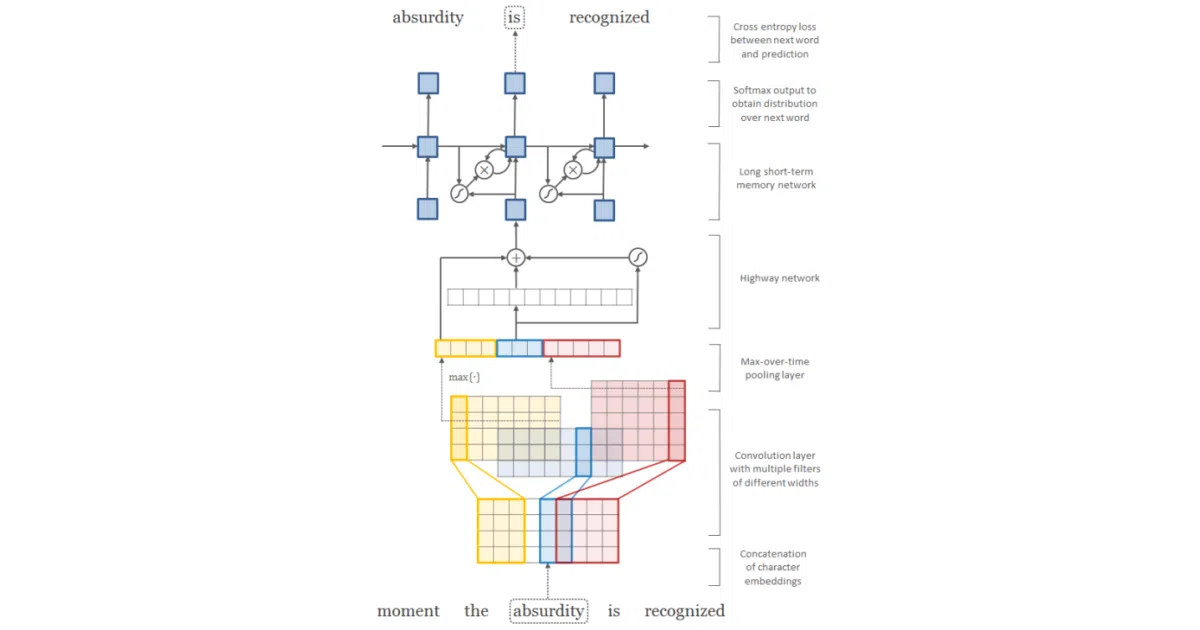
This repo implements a neural language model that builds word representations from characters using a CNN, passes them through highway networks, then feeds them into an LSTM. The idea is to let rare or misspelled words still get meaningful embeddings by decomposing them into character n-grams. It supports both word-level and character-level modes, with the Penn Treebank dataset as the default testbed.
The interesting bit
The architecture itself was genuinely novel for 2016: a CNN over characters with multiple kernel widths (1–7), stacked highway layers for nonlinear transformation, then an LSTM on top. The original paper showed strong perplexity numbers; this repo’s README openly admits it failed to reproduce them and points to a competing implementation that succeeded.
Key highlights
- Character CNN with 7 different kernel widths, feeding into highway networks then LSTM
- Toggle between character-level and word-level modes via CLI flags (
--use_char,--use_word) - Supports both LSTM and LSTMTDNN variants (the latter appears to be a temporal convolution variant)
- Python 2.7/3.3+ with TensorFlow, straightforward
main.pyinterface - Author candidly flags a performance issue in Issue #3 and unreproduced paper results
Caveats
- Performance issue unresolved (see Issue #3); the README warns of this explicitly
- Results not reproduced: paper reported 92.3 and 78.9 perplexity for small/large models; this repo lists “in progress” for both
- Last meaningful update appears to be February 2016 based on the dated performance note
Verdict
Worth a look if you’re studying the evolution of character-level NLP architectures or want to see how early TensorFlow implementations structured complex multi-stage models. Skip it if you need working, benchmarked code—use mkroutikov/tf-lstm-char-cnn instead, which the author themselves recommends.
Frequently asked
- What is carpedm20/lstm-char-cnn-tensorflow?
- TensorFlow reimplementation of Yoon Kim's character-level LSTM language model, stalled with known performance issues and unreproduced benchmarks.
- Is lstm-char-cnn-tensorflow open source?
- Yes — carpedm20/lstm-char-cnn-tensorflow is open source, released under the MIT license.
- What language is lstm-char-cnn-tensorflow written in?
- carpedm20/lstm-char-cnn-tensorflow is primarily written in Python.
- How popular is lstm-char-cnn-tensorflow?
- carpedm20/lstm-char-cnn-tensorflow has 788 stars on GitHub.
- Where can I find lstm-char-cnn-tensorflow?
- carpedm20/lstm-char-cnn-tensorflow is on GitHub at https://github.com/carpedm20/lstm-char-cnn-tensorflow.