carpedm20/deep-rl-tensorflow
A 2016 time capsule of Atari-playing neural nets, frozen in TensorFlow 0.12
Before Stable Baselines existed, this was how you reproduced DeepMind's DQN papers in one codebase.
Not currently ranked — collecting fresh signals.
star history
What it does
Bundles implementations of four foundational Deep Q-Learning variants—DQN, Double DQN, Dueling DQN, and Dueling Double DQN—into a single TensorFlow training script. Feed it an OpenAI Gym environment (Breakout, a debug corridor, or anything else), flip a few flags, and watch a convolutional net learn to mash buttons.
The interesting bit
The whole architecture is controlled by CLI flags: --network_header_type, --network_output_type, --double_q. That design makes it trivial to ablate which paper’s trick actually matters for your problem. The README even includes a toy corridor environment for quick sanity checks without burning GPU hours on Atari frames.
Key highlights
- Implements four papers from the 2015–2016 DQN family in one repo
- Switch architectures via command-line flags (
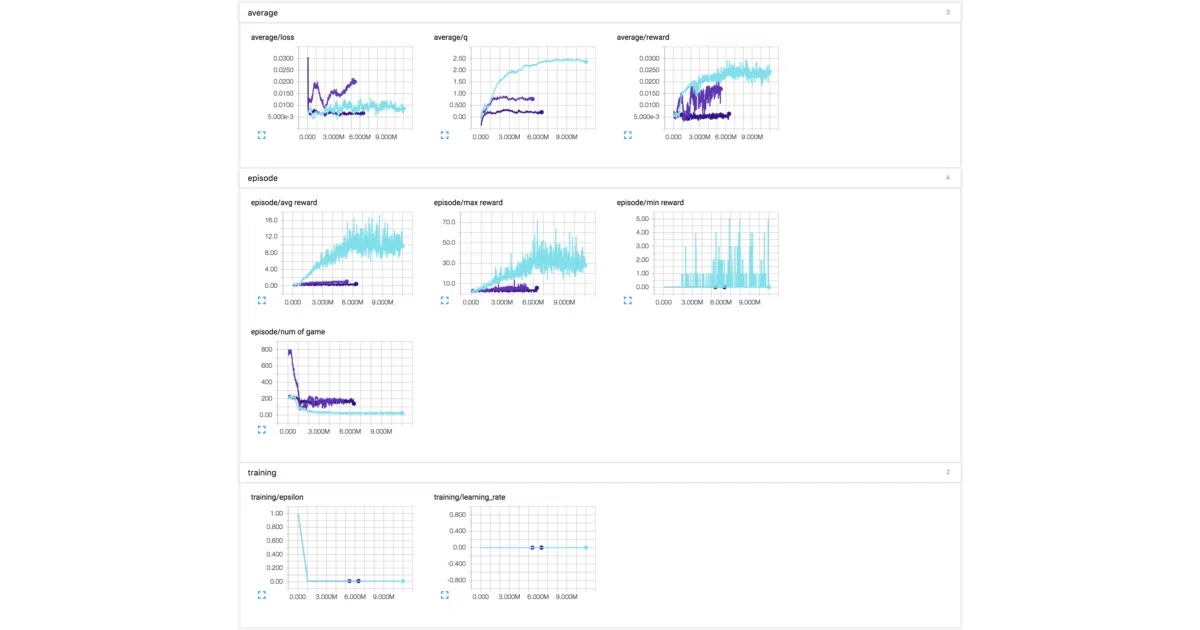
nipsvsnatureheaders,duelingoutput,double_q) - Includes actual training curves comparing DQN / DDQN / Dueling on Corridor-v5 and Breakout-v0
- Provides a lightweight MLP mode for debugging with tiny state spaces
Caveats
- Requires Python 2.7 and TensorFlow 0.12.0—archaeology, not production
- Four later papers (Prioritized Replay, A3C, Bootstrapped DQN, Continuous DQN) are marked “in progress” with no visible code
- README notes hyperparameters and gradient clipping deviate from the original papers
Verdict
Worth a skim if you’re studying how early DQN implementations were structured, or need a clean before-and-after comparison of Double Q-learning and Dueling architectures. Skip it if you want something that runs on modern Python without a conda time machine.
Frequently asked
- What is carpedm20/deep-rl-tensorflow?
- Before Stable Baselines existed, this was how you reproduced DeepMind's DQN papers in one codebase.
- Is deep-rl-tensorflow open source?
- Yes — carpedm20/deep-rl-tensorflow is open source, released under the MIT license.
- What language is deep-rl-tensorflow written in?
- carpedm20/deep-rl-tensorflow is primarily written in Python.
- How popular is deep-rl-tensorflow?
- carpedm20/deep-rl-tensorflow has 1.6k stars on GitHub.
- Where can I find deep-rl-tensorflow?
- carpedm20/deep-rl-tensorflow is on GitHub at https://github.com/carpedm20/deep-rl-tensorflow.