byzer-org/byzer-lang
SQL that swallows REST APIs and spits out Delta tables
Byzer-lang treats everything as a table, including JSON endpoints you'd rather not parse by hand.
Not currently ranked — collecting fresh signals.
star history
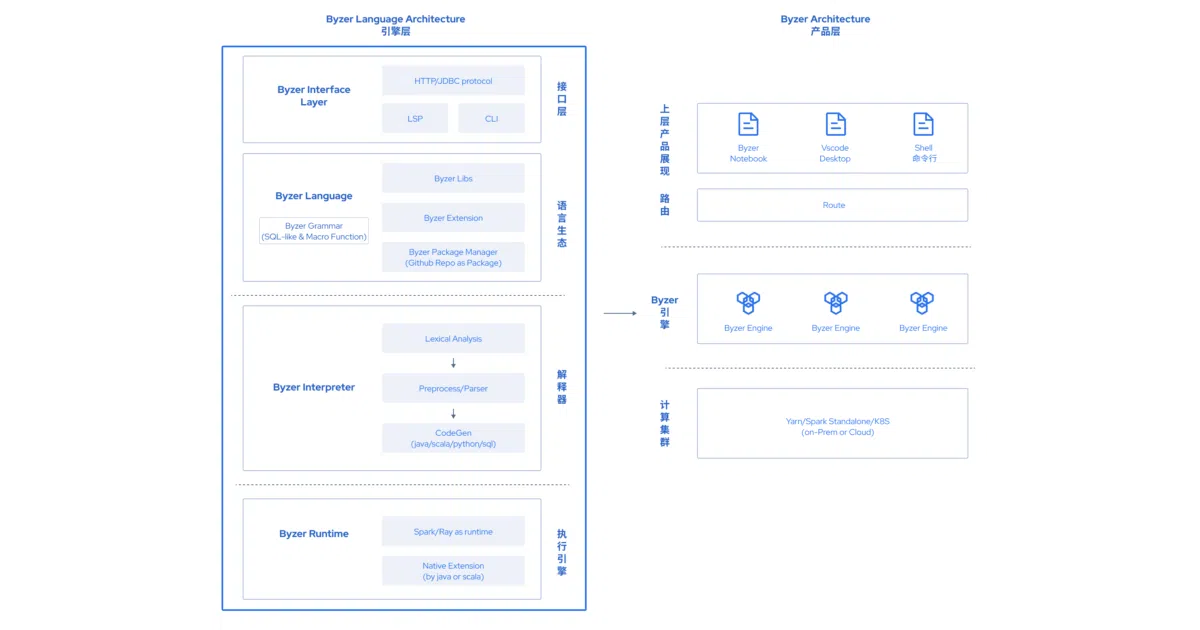
What it does Byzer-lang is a SQL-like DSL that wraps Spark and other compute frameworks so you never touch them directly. You write declarative pipelines to load data (from REST APIs, files, or elsewhere), transform it, run built-in ML algorithms, and save to Delta Lake — all in one dialect. The project also ships a notebook UI and VS Code extension for good measure.
The interesting bit
The “everything is a table” philosophy gets pushed further than usual: the README shows a GitHub API call ingested via LOAD Rest.\``, decoded from binary, JSON-expanded, and saved to Delta without leaving SQL syntax. It’s not just querying tables; it’s tabularizing the untabular.
Key highlights
- Distributed execution backed by Spark (3.0.0 profile visible in build config), though you interact only with Byzer’s engine
- Built-in extensions for JSON expansion, ML algorithms, and other data/AI tasks
- Multiple entry points: local all-in-one package, Hadoop deployment, Docker, VS Code extension, or online trial
- Active BIP (Byzer Improvement Proposal) process for community-driven design
- Companion project Byzer Notebook for GUI workflow editing
Caveats
- Documentation links in the README point heavily to Chinese-language pages; English coverage is unclear
- Development setup requires specific IntelliJ Maven profiles (scala-2.12, spark-3.0.0, etc.) — not the smoothest on-ramp
- The “low-code” claim is fair for pipeline logic, but you’ll still need to understand Spark deployment for production
Verdict Worth a look if your team lives in SQL but keeps hitting friction with Python/Scala glue code for ETL and light ML. Skip it if you need deep framework control or a mature, English-first documentation ecosystem.
Frequently asked
- What is byzer-org/byzer-lang?
- Byzer-lang treats everything as a table, including JSON endpoints you'd rather not parse by hand.
- Is byzer-lang open source?
- Yes — byzer-org/byzer-lang is open source, released under the Apache-2.0 license.
- What language is byzer-lang written in?
- byzer-org/byzer-lang is primarily written in Scala.
- How popular is byzer-lang?
- byzer-org/byzer-lang has 1.8k stars on GitHub.
- Where can I find byzer-lang?
- byzer-org/byzer-lang is on GitHub at https://github.com/byzer-org/byzer-lang.