buppt/ChineseNER
A 2018 time capsule for Chinese NER that still gets stars
A deliberately simple BiLSTM+CRF implementation for Chinese named-entity recognition, frozen in the amber of Python 2.7 and TensorFlow 1.7.
Not currently ranked — collecting fresh signals.
star history
What it does
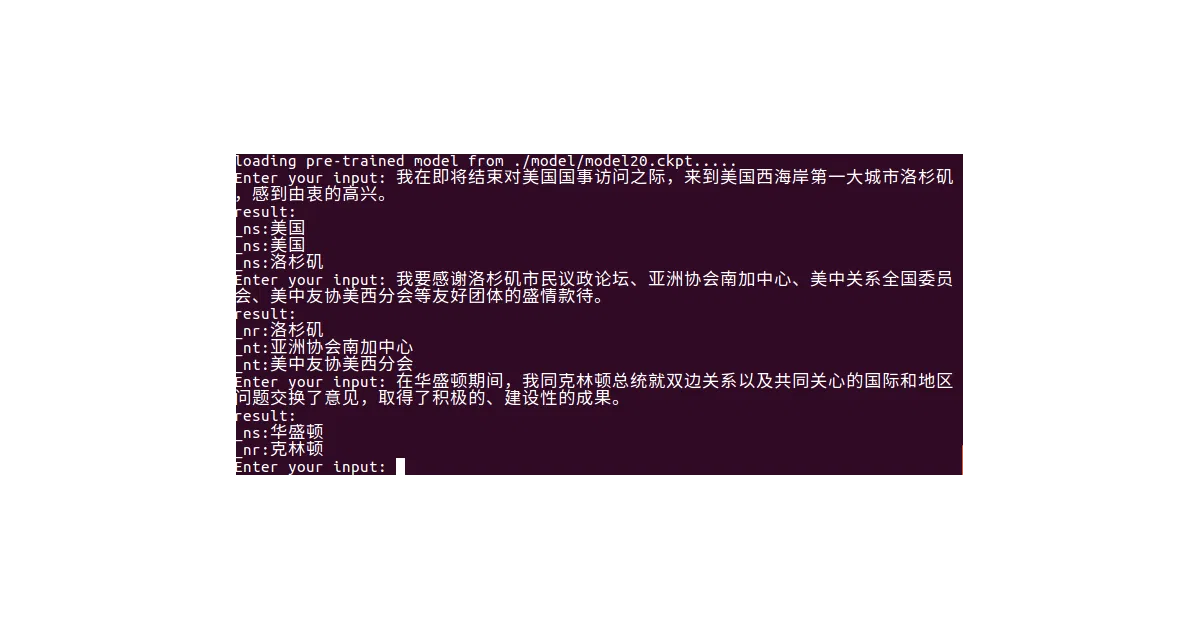
Trains a BiLSTM+CRF model to extract named entities from Chinese text—people, places, organizations, and a few others depending on the dataset. Ships with three built-in datasets (Boson, 1998 People’s Daily, MSRA) and supports both training from scratch and using pretrained word vectors. Can also batch-process files: feed it input.txt, get output.txt with tagged entities.
The interesting bit The author is admirably blunt about what this is: “the simplest” such model, with parameters “not tuned too carefully.” The PyTorch version is essentially the official PyTorch tutorial code, running on CPU without batching, which the README admits is “super slow.” That honesty is refreshing—and the 1,463 stars suggest plenty of people still want a minimal working baseline they can actually read.
Key highlights
- Dual implementations: TensorFlow (maintained) and PyTorch (frozen, CPU-only, no batching)
- Three datasets ready to run after a preprocessing script
- CLI supports training, testing, pretrained vectors, and file-level extraction
- F-scores around 85–90% on 3-class datasets (People’s Daily, MSRA), 70–75% on 6-class Boson
- Includes a small pretrained word vector file (
vec.txt) for quick experiments
Caveats
- Locked to Python 2.7, TensorFlow 1.7, and PyTorch 0.4.0—expect dependency archaeology
- PyTorch branch explicitly abandoned; author suggests using only partial data “if you just want to run the code simply”
- No model architecture details or ablation studies; this is glue-and-boilerplate, not research
Verdict
Grab this if you need a readable, no-magic baseline for Chinese NER and don’t mind wrestling with 2018 dependencies. Skip it if you want production-ready code, modern frameworks, or anything approaching SOTA—there are newer Chinese NER repos that won’t require you to excavate pip install history.
Frequently asked
- What is buppt/ChineseNER?
- A deliberately simple BiLSTM+CRF implementation for Chinese named-entity recognition, frozen in the amber of Python 2.7 and TensorFlow 1.7.
- Is ChineseNER open source?
- Yes — buppt/ChineseNER is an open-source project tracked on heatdrop.
- What language is ChineseNER written in?
- buppt/ChineseNER is primarily written in Python.
- How popular is ChineseNER?
- buppt/ChineseNER has 1.5k stars on GitHub.
- Where can I find ChineseNER?
- buppt/ChineseNER is on GitHub at https://github.com/buppt/ChineseNER.