batzner/indrnn
RNN neurons that refuse to talk to each other
A TensorFlow implementation of IndRNN, where each recurrent neuron carries its own weight and its own baggage.
Not currently ranked — collecting fresh signals.
star history
What it does
Implements Independently Recurrent Neural Networks in TensorFlow 1.x. The core change: instead of a full weight matrix connecting hidden states (U * state), IndRNN uses element-wise multiplication (u * state), so each neuron only talks to its own past self. You copy one file (ind_rnn_cell.py) and drop it into your project as a custom RNN cell.
The interesting bit
The independence is the point. Because neurons don’t cross-talk in the recurrent step, you can use ReLU without the usual gradient fireworks, stack layers deeper, and actually interpret what each neuron is doing. The paper also claims this structure prevents vanishing and exploding gradients by bounding each neuron’s single recurrent weight.
Key highlights
- Single-file implementation:
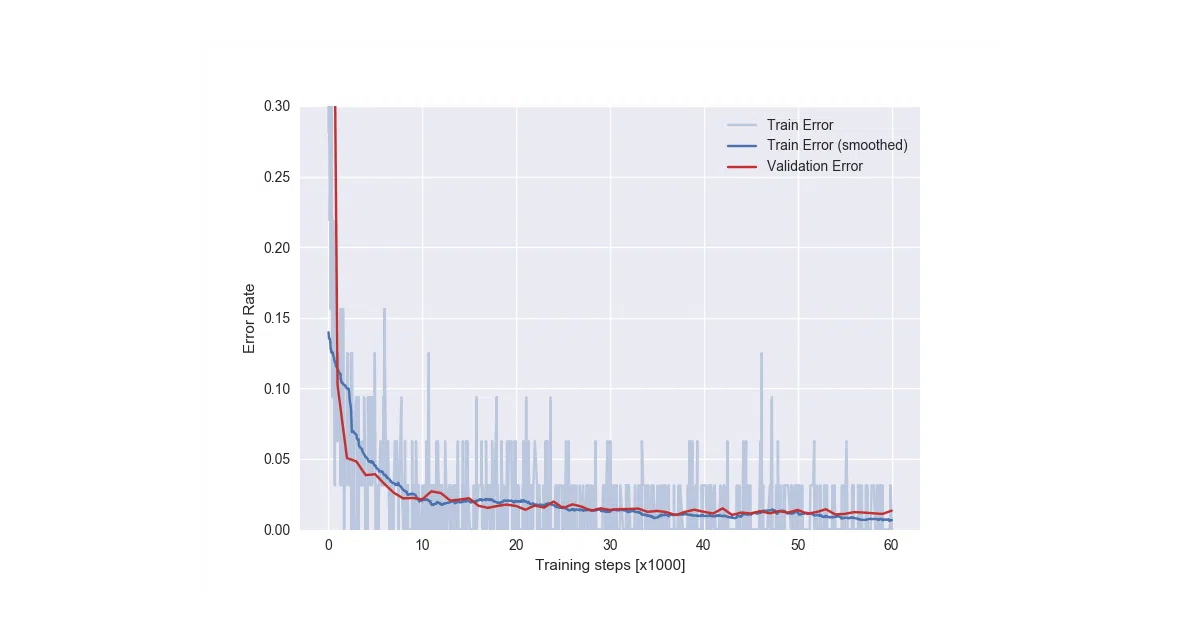
ind_rnn_cell.pywith anIndRNNCellclass - Reproduces two paper experiments: the “Adding Problem” and Sequential MNIST (1.1% test error after 60K steps)
- Supports regulated recurrent weights via
recurrent_max_absparameter - Compatible with TensorFlow’s
MultiRNNCellanddynamic_rnn - Requires TensorFlow 1.5+ and Python 3.4+
Caveats
- Built for TensorFlow 1.x (
tf.nn.dynamic_rnn); no indication of TF 2.x or Keras compatibility - Sequential MNIST training was manually stopped after two days, so convergence behavior is unclear
Verdict
Worth a look if you’re stuck maintaining legacy TF 1.x code or genuinely curious about structured RNN alternatives. Skip it if you’re already committed to TF 2.x/Keras or transformers; this is a clean paper implementation, not a maintained framework.
Frequently asked
- What is batzner/indrnn?
- A TensorFlow implementation of IndRNN, where each recurrent neuron carries its own weight and its own baggage.
- Is indrnn open source?
- Yes — batzner/indrnn is open source, released under the Apache-2.0 license.
- What language is indrnn written in?
- batzner/indrnn is primarily written in Python.
- How popular is indrnn?
- batzner/indrnn has 513 stars on GitHub.
- Where can I find indrnn?
- batzner/indrnn is on GitHub at https://github.com/batzner/indrnn.