baidu/Unlimited-OCR
Baidu’s OCR model treats page limits as a suggestion
It wants to parse entire documents in one shot without the model getting stuck in repetitive loops.
Feature · 24 Jun 2026
Baidu’s Unlimited OCR Bets on a Fixed KV Cache for Long Books
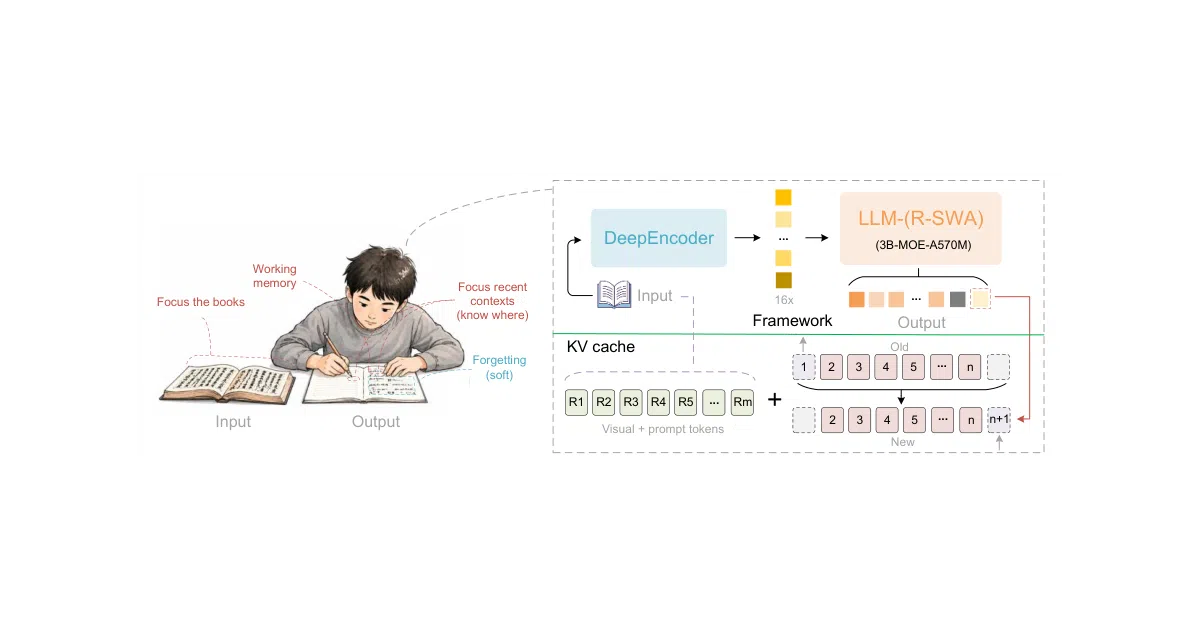
An open-source document parser uses Reference Sliding Window Attention to process hundred-page PDFs in one forward pass without letting memory explode.
Read the in-depth article →
Collecting fresh signals — velocity needs a few days of history.
collecting data…
star history
What it does
Unlimited OCR Works is a Baidu-built document parsing model that ingests single images or multi-page PDFs and emits structured text in a single inference pass. It runs via Hugging Face Transformers or an SGLang server and offers two single-image modes—gundam and base—alongside a multi-page pipeline that rasterizes PDFs into images for processing. The README focuses almost entirely on inference setup and leaves the underlying architecture unexplained.
The interesting bit
The model fights long-horizon hallucination and repetition with a custom DeepseekOCRNoRepeatNGramLogitProcessor that bans 35-grams inside a sliding window—128 tokens for single images, 1024 for multi-page. That is the actual mechanism behind the “unlimited” claim; it is less about infinite context and more about not getting bored halfway through a book.
Key highlights
- Supports single-image
gundammode (cropped, 640 px) and fullbasemode (1024 px). - Multi-page and PDF parsing via
infer_multi, though PDFs must first be converted to images with PyMuPDF. - Ships with a custom no-repeat n-gram logit processor to prevent degenerate loops during long outputs.
- Serves an OpenAI-compatible API through SGLang for batch or streaming use.
- Explicitly positioned as a successor to DeepSeek-OCR, borrowing ideas from PaddleOCR.
Caveats
- The README claims to push past DeepSeek-OCR but offers no benchmarks or side-by-side comparisons to prove it.
- SGLang setup instructions list conflicting
kernelsversions (0.9.0in prose,0.11.7in the code block). - PDF support is indirect: pages are rasterized to PNGs at a chosen DPI rather than parsed natively.
Verdict
Worth a look if you are building pipelines that need to OCR hundred-page PDFs in a single pass and can tolerate rasterized inputs. Skip it if you need native PDF extraction, quantified accuracy claims, or a detailed model card.