baidu/Unlimited-OCR · 24 Jun 2026 · Feature
Baidu’s Unlimited OCR Bets on a Fixed KV Cache for Long Books

Nathan Brooks
Staff Writer
An open-source document parser uses Reference Sliding Window Attention to process hundred-page PDFs in one forward pass without letting memory explode.
baidu/Unlimited-OCR
★3.8k stars
The Anime Title and the Memory Wall
In late June 2026, Baidu released a model whose name sounds like an anime ultimate technique: Unlimited OCR Works [1][10]. The allusion is almost certainly intentional—like its namesake, the project promises to generate an infinite supply of something, in this case parsed text from scanned documents. Announced on June 22 and detailed in an arXiv preprint the following day, the repository explicitly frames itself as the next step beyond DeepSeek-OCR and DeepSeek-OCR-2, with acknowledgements to PaddleOCR as well [1][2]. The tagline—“Welcome the Era of One-shot Long-horizon Parsing”—is less poetic but more telling. Baidu is not merely improving character recognition accuracy; it is trying to eliminate the page-by-page for-loop that has long defined large-scale document digitization [2][5].
Why Long Documents Break Ordinary OCR
Traditional OCR extracts text; modern pipelines must extract structure, context, and meaning. The industry has spent years shifting from template-based systems—brittle when confronted with handwritten notes, embedded tables, or skewed scans—toward Vision Language Models and agentic workflows that interpret layout rather than blindly transcribe it [3][6]. Yet even advanced VLMs hit a physical wall when asked to process a 500-page legal archive or a decade of procurement records in one go. In standard transformer decoding, every new token attends to all previous tokens. The key-value cache therefore grows linearly with sequence length, and for long documents it eventually overwhelms GPU memory, forcing throughput to collapse [2]. The pragmatic workaround, used by predecessors such as DeepSeek OCR, is to reset the model state and process each page in a fresh forward pass. This works, but it fragments context, breaks cross-page tables, and turns batch conversion into a serial chore [2].
For enterprises sitting on scanned contracts, engineering drawings, faxed memoranda, and compliance packs, this friction is expensive. A LinkedIn discussion around the launch highlighted the “company brain” use case: organizations attempting to digitize fifty years of enterprise knowledge trapped in hard copies and proprietary file formats [5]. The goal is not a text dump, but a structured, machine-readable knowledge base that can feed future agentic workflows [5]. Mortgage lenders, meanwhile, process thousands of daily applications containing diverse, poorly formatted, or handwritten documents; manual review previously required one to two days per application [6].
Reference Sliding Window Attention
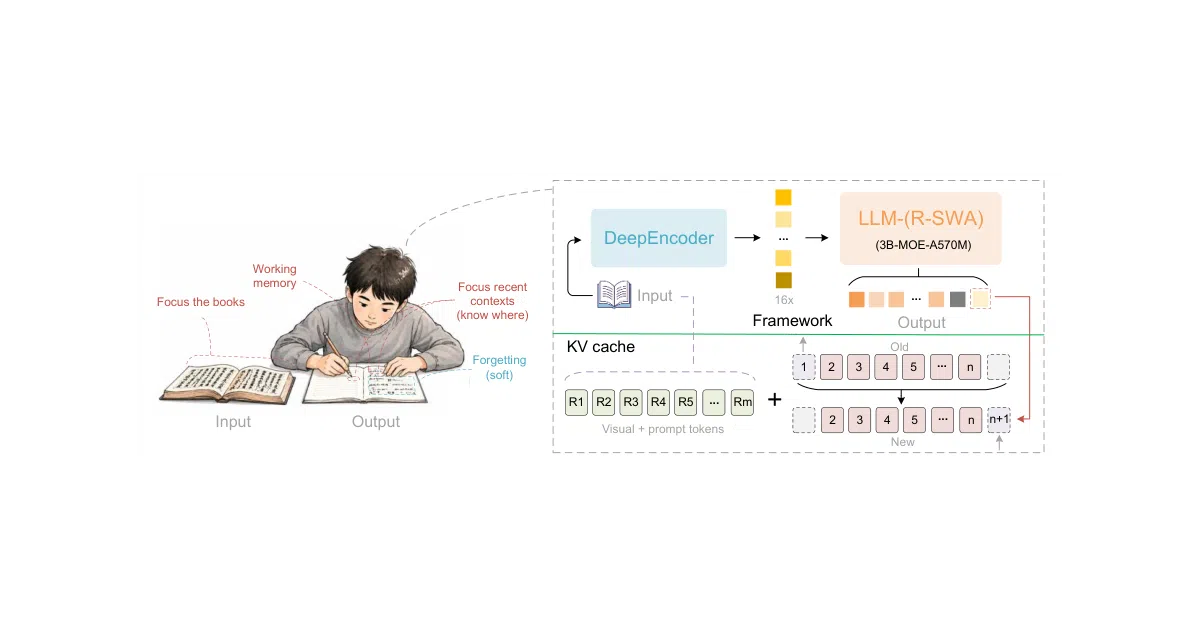
The technical centerpiece of Unlimited OCR is Reference Sliding Window Attention, or R-SWA [2]. Baidu’s authors replaced every decoder attention layer with a mechanism that treats reference tokens—visual embeddings and user prompts—differently from the model’s own generated output. Each new token attends to the full set of reference tokens, preserving the fidelity of the input image and instructions. For the autoregressive output stream, however, attention is restricted to a sliding window of the preceding 128 tokens [2].
This split design keeps the KV cache constant regardless of how many pages are being parsed. Because the reference tokens are excluded from the sliding window’s state transitions, they avoid the progressive blurring that vanilla sliding window attention inflicts on long visual sequences [2]. In other words, the model does not slowly forget what the page looks like simply because it has already written ten thousand tokens of markdown. The architecture is grafted onto DeepSeek OCR’s high-compression DeepEncoder, inheriting its visual backbone while rewriting how the decoder remembers what it has already written [2].
The result is a model that can theoretically ingest dozens of pages—or an entire scanned book—within a single 32,768-token forward pass [2][10]. On OmniDocBench v1.5, it scores 93 percent, a six-point improvement over the DeepSeek OCR baseline [2]. The authors note only modest general OCR accuracy gains elsewhere, suggesting the real dividend is throughput and memory stability on long horizons rather than a universal leap in single-page acuity [2]. They further position R-SWA as a general-purpose parsing mechanism applicable to automatic speech recognition, translation, and any other reference-based long-horizon task [2].
Two Modes and a Hardware Profile
Unlimited OCR ships with two distinct operational personalities. “Gundam mode” applies dynamic cropping to single images at 640-pixel resolution, while “base mode” processes multi-page PDFs and images at 1024-pixel resolution [1][10]. The naming convention is playful, but the distinction is practical: single-page layouts with dense diagrams may benefit from aggressive cropping, whereas multi-page documents need consistent full-resolution treatment to preserve reading order and table continuity.
The system caps output at 32,768 tokens and deploys a custom n-gram logit processor to suppress repetitive loops—a known pathology in transformer-based OCR [1][10]. It runs on NVIDIA GPUs via Hugging Face Transformers in bfloat16, or through an SGLang inference server using Flash Attention 3 and an OpenAI-compatible streaming API [1]. PDF ingestion relies on PyMuPDF rendering pages at 300 DPI before they ever reach the vision encoder [1]. Batch concurrency is supported, and the stack can run fully offline for privacy-sensitive archives [5]. That said, the hardware requirements are modern: CUDA 12.9 and recent PyTorch versions, meaning “local” still implies a well-equipped machine room rather than a laptop [1].
The Old Guard and the New Stack
To appreciate where Unlimited OCR fits, consider the broader tooling landscape. Legacy services such as OCR.space and NewOCR offer browser-based transcription with broad language support, but they remain essentially digitization utilities—text in, formatting out [4][9]. Olocr runs locally in the browser, yet it is still fundamentally a page-at-a-time consumer tool [12]. On the enterprise side, modular platforms like LlamaParse and Docling orchestrate multiple stages—layout analysis, markdown conversion, RAG ingestion—through pipelines that mix open models with proprietary APIs [3]. Google Document AI, Azure Form Recognizer, and AWS Textract sit at the managed-service end of the spectrum, offering pre-trained extraction with domain-specific fine-tuning [6].
Unlimited OCR is not a pipeline; it is a monolithic end-to-end model. That makes it architecturally closer to DeepSeek OCR than to LlamaIndex’s agentic stack. The bet is that a single forward pass through a constant-memory decoder can replace fragmented OCR chains for bulk archive conversion [2][10]. Where agentic systems might reason over a document in discrete steps—classifying, extracting, validating—Unlimited OCR attempts to internalize all of that reasoning inside one generative loop.
Limits and the Unresolved Tension
The project is only days old. At the time of writing, its Hugging Face repository contained a single initial commit hosting nothing but a 460 kB PDF, with no README or documentation beyond the file itself [7]. The GitHub repository is more complete, though its documentation leans heavily on inference configuration rather than architectural exposition [1]. These are early signals, not sins, but they remind us that the paint is still wet.
There are substantive questions, too. A six-percent benchmark lift is respectable, yet it suggests Unlimited OCR is refining an existing paradigm rather than inventing a new one [2]. The 32K context window, while generous, is now standard among frontier models; the name Unlimited sells infinity, but the silicon currently imposes a ceiling [2][10]. The n-gram repetition processor, meanwhile, is a tell: even with R-SWA, the model still needs guardrails to stop itself from looping [1]. The n-gram window sizes also differ oddly between single-image and multi-page modes—128 versus 1024—hinting that repetition pressure scales non-linearly with output length, though the authors do not explain why [1].
And while the SGLang deployment path promises throughput, it also demands significant GPU memory and recent driver stacks, narrowing the set of organizations that can run it privately [1]. Perhaps the deepest tension is between monolithic end-to-end parsing and the modular, agentic approach championed by the broader document-AI ecosystem [3][6]. A single forward pass is elegant, but it offers fewer opportunities for human-in-the-loop correction or staged validation than a pipeline of discrete extraction, enrichment, and validation modules [6]. If a 400-page mortgage file contains one unusual rider clause, an agentic system might flag it for review; a monolithic VLM might simply hallucinate or skip it.
Where the Architecture Goes Next
Baidu’s authors frame R-SWA not merely as an OCR trick, but as a general-purpose mechanism for any reference-based long-horizon task—automatic speech recognition, translation, and beyond [2]. If the technique holds, it could migrate into other generative domains where KV-cache bloat currently forces chunking and context resets.
For now, Unlimited OCR’s most immediate impact is likely to be felt in digitization factories: the unglamorous backend work of converting scanned books, legal archives, and engineering manuals into structured markdown that large language models can actually consume [5][10]. Whether that justifies the anime title will depend on whether the fixed-size cache can outlast the ever-growing documents enterprises keep discovering in their basements.
Sources
- baidu/Unlimited-OCR - Hugging Face
- Unlimited OCR Works Welcome the Era of One-shot Long-horizon ...
- Best Document Parsing Software: From Legacy OCR to Agentic AI
- Free OCR API V2026, Online OCR, Searchable PDF Creator and ...
- Mitko Vasilev's Post - LinkedIn
- Beyond OCR: How AI is Transforming Document Processing ... - InfoQ
- Unlimited-OCR.pdf · baidu/Unlimited-OCR at main - Hugging Face
- Any enterprise OCR software that can handle complex documents?
- Free Online OCR - Convert JPEG, PNG, GIF, BMP, TIFF, PDF, DjVu ...
- Baidu Releases Unlimited OCR for One-shot Long-horizon Parsing
- OCR vs. Document Processing - Understanding the Difference
- OLOCR: Online AI OCR - Extract Text from Images & PDFs