baidu/AnyQ
Baidu's FAQ engine: 20+ plugins, one config file
A C++ framework for building FAQ chatbots that mixes classical IR with neural matching, straight out of Baidu's NLP department.
Not currently ranked — collecting fresh signals.
star history
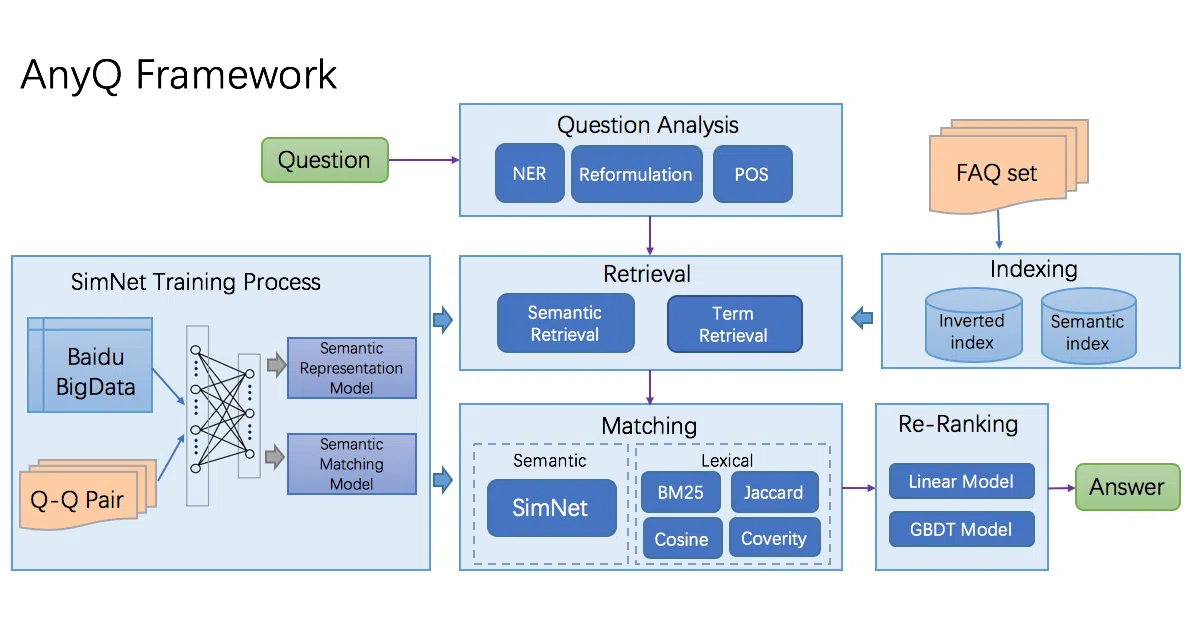
What it does AnyQ is a configurable, plugin-based FAQ question-answering system. You feed it a set of question-answer pairs, and it handles the rest: analyzing the incoming question, retrieving candidates via inverted index or semantic search, matching with both lexical and neural features, and re-ranking. It ships with 20+ plugins covering Chinese word segmentation, Solr-based retrieval, BM25/Jaccard/Cosine matching, and SimNet neural semantic matching.
The interesting bit The real payload is SimNet, Baidu’s in-house semantic matching framework (circa 2013) that runs on PaddleFluid and TensorFlow. It bundles both representation-based models (BOW, CNN, RNN) and interaction-based models (MatchPyramid, MV-LSTM, K-NRM). Baidu claims their pre-trained SimNet-BOW model beats literal similarity methods by 5%+ AUC on real FAQ data — though they don’t specify which datasets.
Key highlights
- Modular pipeline: Question Analysis → Retrieval → Matching → Re-Rank, all swappable via config
- Dual retrieval: classical Solr inverted index + ANNOY-based approximate nearest neighbor semantic search
- SimNet supports both PaddleFluid and TensorFlow backends with extensible model definitions
- HTTP server and C++ library interfaces both included
- Docker images provided for macOS/Windows; Linux builds need cmake 3.0+, g++ ≥4.8.2, bison ≥3.0
Caveats
- Documentation is primarily in Chinese; English README exists but may lag
- Pre-trained model claims lack reproducible benchmarks or dataset names
- Build dependencies are dated (cmake 3.2.2 “recommended”, g++ 4.8.2 minimum)
Verdict Worth a look if you’re building Chinese-language FAQ bots and want a battle-tested retrieval-plus-neural pipeline without writing glue code. Skip if you need modern transformer-based models or extensive English-language support — the ecosystem here is firmly 2013-2018 era deep learning.
Frequently asked
- What is baidu/AnyQ?
- A C++ framework for building FAQ chatbots that mixes classical IR with neural matching, straight out of Baidu's NLP department.
- Is AnyQ open source?
- Yes — baidu/AnyQ is open source, released under the Apache-2.0 license.
- What language is AnyQ written in?
- baidu/AnyQ is primarily written in C++.
- How popular is AnyQ?
- baidu/AnyQ has 2.6k stars on GitHub.
- Where can I find AnyQ?
- baidu/AnyQ is on GitHub at https://github.com/baidu/AnyQ.