aryn-ai/sycamore
ETL for documents that actually reads the charts
Sycamore uses a vision model trained on 80k+ enterprise documents to segment PDFs and images before chunking them for search or RAG.
Not currently ranked — collecting fresh signals.
star history
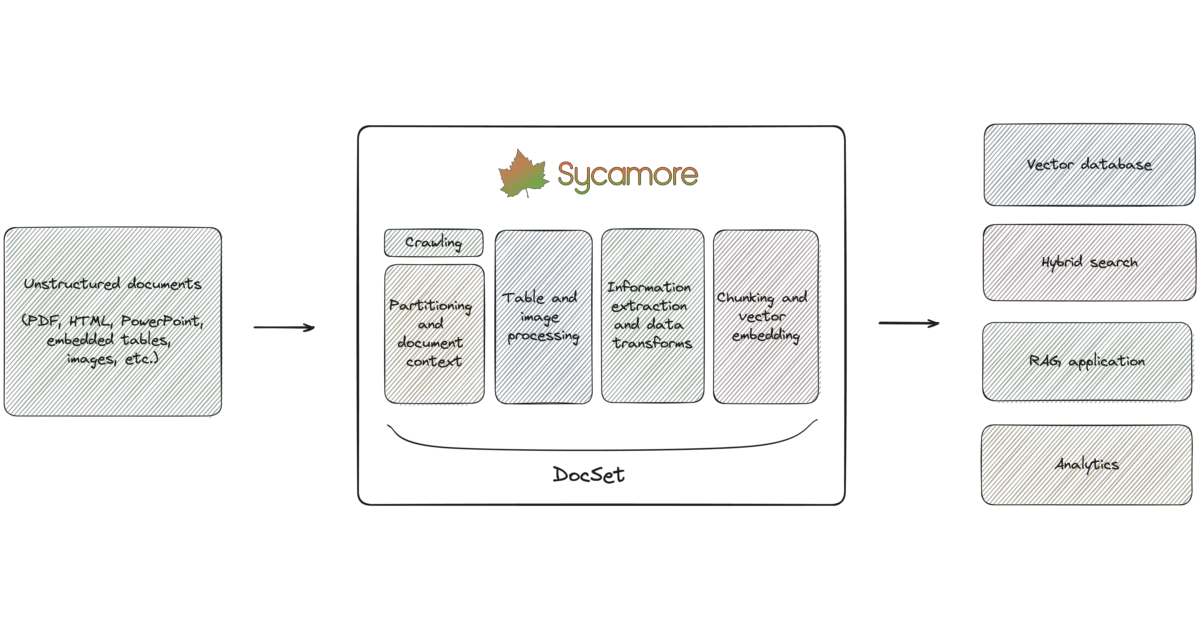
What it does Sycamore is a Python document processing framework that ingests unstructured files—PDFs, presentations, images with embedded tables—and transforms them into clean, chunked data for vector databases or hybrid search engines. It wraps the messy pipeline of OCR, table extraction, visual summarization, and embedding generation into a functional programming abstraction called a DocSet.
The interesting bit The project leans heavily on Aryn DocParse, a GPU-powered API that runs an open-source deformable DETR model trained specifically on document layout. The claim is 6x better chunking accuracy and 2x improved recall versus alternatives—though the README doesn’t specify which alternatives. The DocSet abstraction then layers scalable transforms (powered by Ray) on top, so you’re not hand-rolling distributed processing for each new document type.
Key highlights
- Integrates with Aryn DocParse for document segmentation using a vision model; local execution is optional if you prefer not to use the cloud API
- DocSet abstraction provides functional Python transforms for enrichment, cleaning, and loading
- Connectors for OpenSearch, ElasticSearch, Pinecone, DuckDB, Qdrant, and Weaviate
- Scalable backend via Ray; includes Jupyter notebook support and an OpenSearch-based test engine for RAG
- Automatic crawlers for S3 and HTTP sources
Caveats
- Linux and Mac OS only; Windows developers are out of luck
- The “6x more accurate” and “2x improved recall” claims lack benchmarks or comparison methodology in the README
- Heavy coupling to Aryn’s ecosystem; the DocParse service requires signup, though local partitioning is possible
Verdict Worth a look if you’re building RAG pipelines over complex documents with tables and figures, and you want someone else to handle the vision-model segmentation. Skip if your documents are mostly plain text or if you need cross-platform support.
Frequently asked
- What is aryn-ai/sycamore?
- Sycamore uses a vision model trained on 80k+ enterprise documents to segment PDFs and images before chunking them for search or RAG.
- Is sycamore open source?
- Yes — aryn-ai/sycamore is open source, released under the Apache-2.0 license.
- What language is sycamore written in?
- aryn-ai/sycamore is primarily written in Python.
- How popular is sycamore?
- aryn-ai/sycamore has 603 stars on GitHub.
- Where can I find sycamore?
- aryn-ai/sycamore is on GitHub at https://github.com/aryn-ai/sycamore.