apecloud/ApeRAG
GraphRAG that actually ships to prod: K8s, MCP, and five index types
ApeRAG wraps hybrid retrieval in a deployable platform so you stop duct-taping vector DBs together.
Not currently ranked — collecting fresh signals.
star history
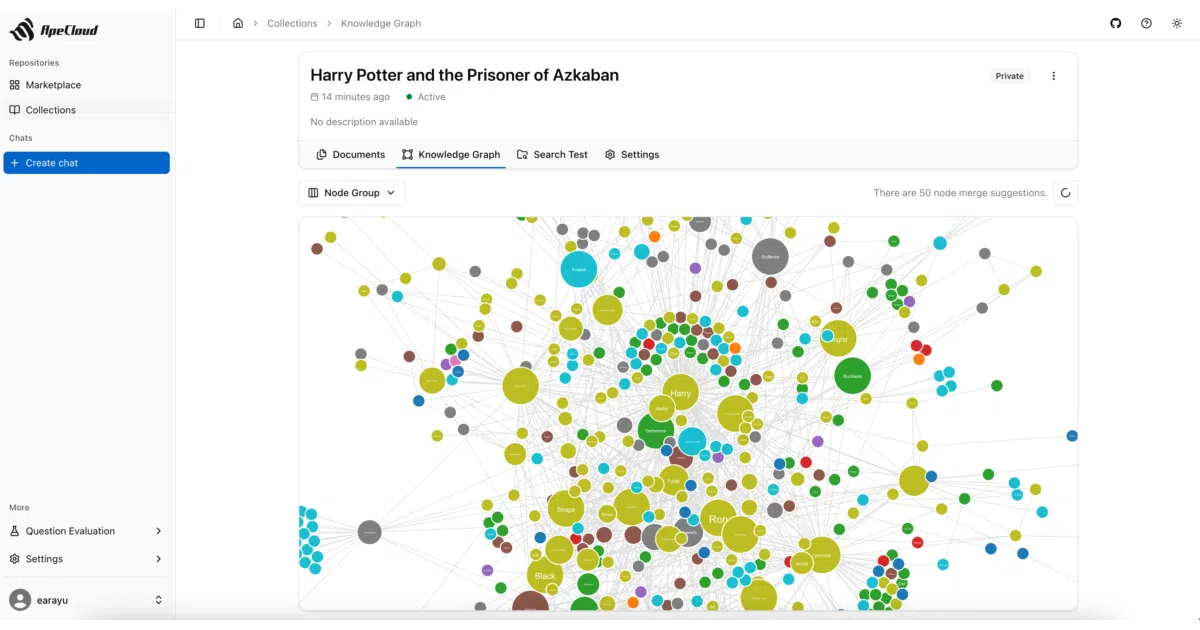
What it does ApeRAG is a full-stack RAG platform built around a “deeply modified” fork of LightRAG. It indexes documents across five parallel channels—vector, full-text, graph, summary, and vision—then exposes them through a FastAPI backend, React UI, and an MCP server so AI assistants can query your knowledge base directly.
The interesting bit The project treats deployment as a first-class feature, not an afterthought. It ships with Helm charts, KubeBlocks automation for PostgreSQL/Redis/Qdrant/Elasticsearch/Neo4j, and optional GPU-accelerated document parsing via MinerU. That’s a lot of moving parts pre-wired.
Key highlights
- Five index types: vector, full-text, graph, summary, and vision
- MCP server for direct assistant integration (collection browsing + hybrid search)
- Modified LightRAG with entity normalization and distributed Celery/Prefect task queues
- MinerU-powered document parsing with optional GPU acceleration
- Full K8s deployment path via Helm + KubeBlocks, plus Docker Compose for local dev
- Built-in audit logging, LLM model management, and graph visualization
Caveats
- Heavy infrastructure appetite: default deployment includes doc-ray (4+ CPU, 8GB+ RAM) and five data stores
- README claims “production-ready” but doesn’t cite specific throughput, latency, or resilience benchmarks
- “Deeply modified” LightRAG means you’re on their fork for graph features
Verdict Worth evaluating if you’re building a knowledge-heavy product and tired of wiring vector DBs, graph stores, and parsing pipelines yourself. Skip it if you just need a quick vector search layer or lack the ops bandwidth for a five-database stack.
Frequently asked
- What is apecloud/ApeRAG?
- ApeRAG wraps hybrid retrieval in a deployable platform so you stop duct-taping vector DBs together.
- Is ApeRAG open source?
- Yes — apecloud/ApeRAG is open source, released under the Apache-2.0 license.
- What language is ApeRAG written in?
- apecloud/ApeRAG is primarily written in Python.
- How popular is ApeRAG?
- apecloud/ApeRAG has 1.3k stars on GitHub.
- Where can I find ApeRAG?
- apecloud/ApeRAG is on GitHub at https://github.com/apecloud/ApeRAG.