aleju/mario-ai
Teaching Mario to jump without falling in its own grave
A 2016-era DQN agent that learns Super Mario World from raw pixels, with a Spatial Transformer to focus on what matters.
Not currently ranked — collecting fresh signals.
star history
What it does
This project trains a deep Q-network to play the first level of Super Mario World using only grayscale screenshots as input—no hand-coded features about enemies, pipes, or power-ups. It runs inside a modified SNES emulator (lsnes) via Lua hooks, captures screens to a ramdisk, and optimizes button presses against a custom reward function that cares about horizontal progress, not score. Score-based rewards were deliberately avoided because enemies respawn, and the agent would happily farm them forever.
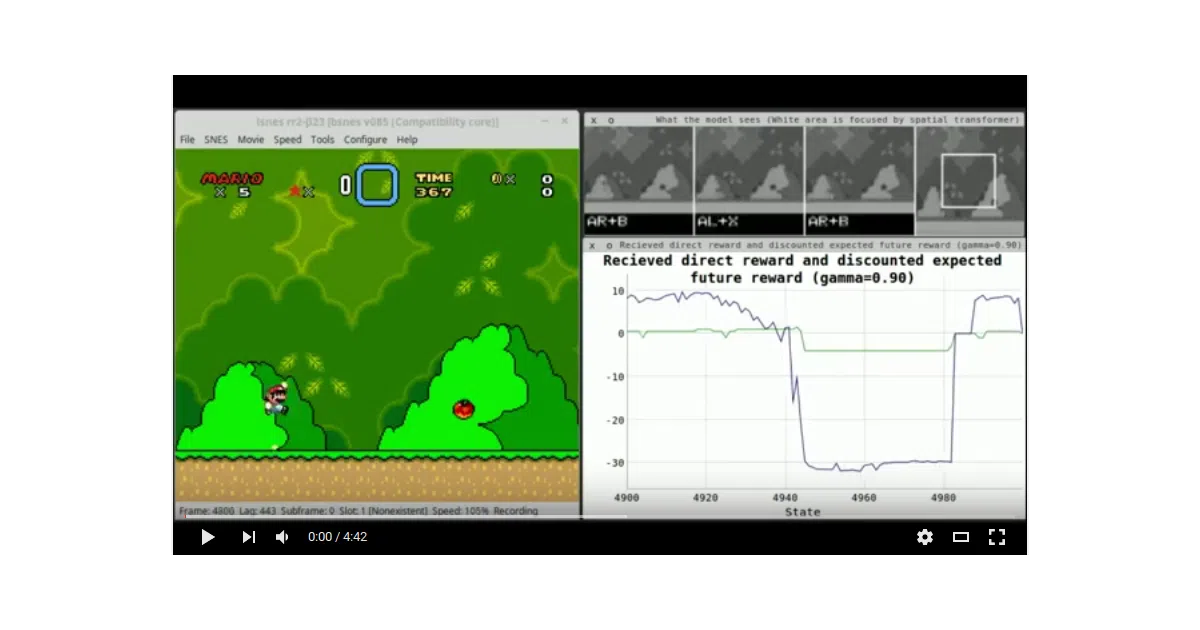
The interesting bit
The network has three branches: one for action history (so it learns to release A before landing), one for low-res motion history, and one for a higher-res current frame with a Spatial Transformer that zooms in on a learned “area of interest.” That’s unusual for 2016-era DQN implementations—most Atari clones just stacked frames and convolved. The selective MSE loss is also neat: gradients are zeroed out for unchosen actions because their true reward is unknown, not zero.
Key highlights
- ~6.6M parameters across the Q-network and its localization net
- Dual-action output: one arrow button + one face button simultaneously (required for running jumps)
- Epsilon-greedy annealing from 0.8 down to 0.1 over 400k actions
- Replay memory of 250k entries with uniform random sampling
- Reward function emphasizes X-velocity: +1.0 for fast rightward movement, -1.5 for fast leftward, -3.0 for death
Caveats
- The install is genuinely arduous: patch and recompile a specific beta of lsnes, set up a ramdisk, install Torch with half a dozen Lua rocks, and pray your CUDA/cuDNN versions match
- The agent is brittle beyond level 1; jumping puzzles, cannons, and high walls expose how epsilon-greedy exploration sabotages learned sequences that require holding A
- Training generalizes poorly across levels because each introduces new mechanics (climbing, squeezing blocks, new enemies)
Verdict
Worth studying if you’re implementing classic DQN with memory replay and want to see how action history and spatial attention were hacked into the pipeline circa 2016. Skip it if you want something that runs today—this is a historical artifact, not a starter kit, and the dependencies have aged about as well as a 1-Up mushroom left in the sun.
Frequently asked
- What is aleju/mario-ai?
- A 2016-era DQN agent that learns Super Mario World from raw pixels, with a Spatial Transformer to focus on what matters.
- Is mario-ai open source?
- Yes — aleju/mario-ai is open source, released under the MIT license.
- What language is mario-ai written in?
- aleju/mario-ai is primarily written in Lua.
- How popular is mario-ai?
- aleju/mario-ai has 692 stars on GitHub.
- Where can I find mario-ai?
- aleju/mario-ai is on GitHub at https://github.com/aleju/mario-ai.