alchaincyf/darwin-skill
A fitness tracker for your AI prompts
Darwin.skill treats prompt engineering like model training: edit, score, revert if it regresses.
Velocity · 7d
+136
★ / day
Trend
↗accelerating
star history
What it does
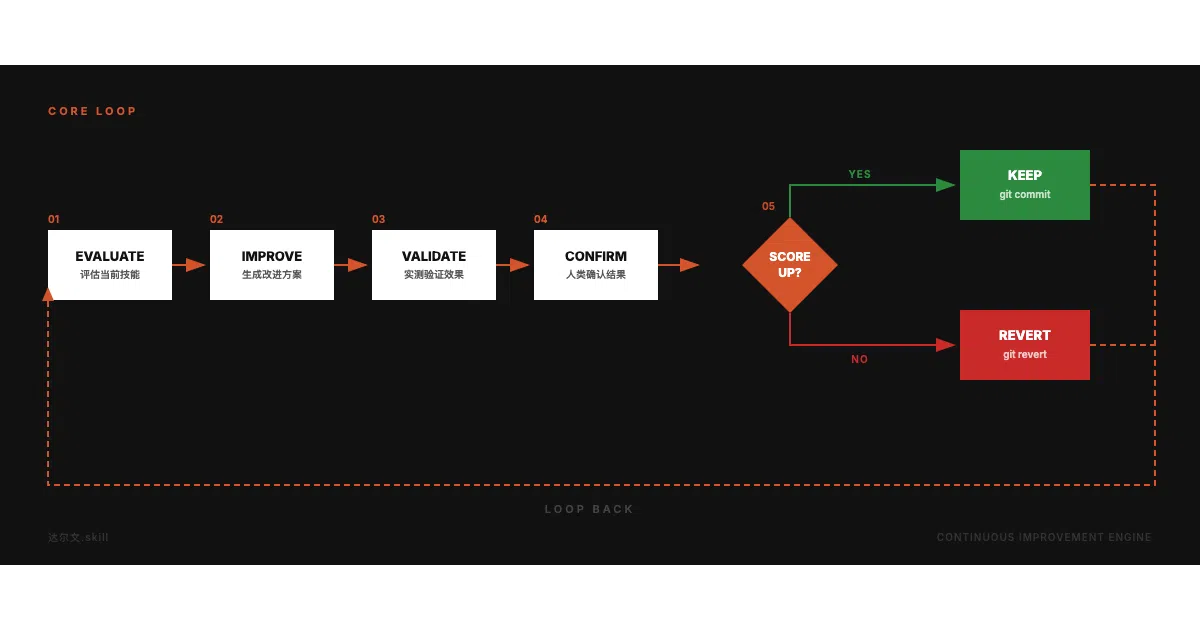
Darwin.skill is a self-optimization system for Claude Code’s SKILL.md files. It borrows Andrej Karpathy’s autoresearch loop — generate a change, validate it, keep only what improves a metric — and applies it to natural-language agent instructions instead of code. You install it via npx skills add, tell it to optimize a skill, and it iterates: edit one dimension, run independent judges, commit or revert, repeat.
The interesting bit
The project is essentially a port of machine-learning infrastructure to a domain with no automatic differentiation. It replaces val_bpb with a 9-dimensional rubric (out of 100), swaps train.py for a SKILL.md file, and uses git revert as its backpropagation. The v2.0 rubric even codifies anti-patterns like “do not say ‘consider’ or ‘as appropriate’” — treating prompt vagueness as a measurable bug class.
Key highlights
- Ratchet mechanism: scores only move upward; any regression is auto-reverted via git, so the skill never quietly rots.
- Independent judges: each round spins up two fresh sub-agents to score the edit, because the README cites SkillLens research showing LLM self-evaluation is only 46.4% accurate.
- Human checkpoints: the system pauses at three gates (baseline review, per-dimension edit, regression test) rather than going fully autonomous.
- Academic grounding: v2.0 explicitly incorporates two Microsoft Research papers (SkillLens and SkillOpt) published May 2026, adding dimensions like “Failure Mechanism Encoding” and “High-Risk Action Blacklist.”
- Reported gains: one skill improved from 80.8 to 91.65 over iterations, with six independent judges concurring.
Caveats
- The README is entirely in Chinese; English documentation exists but is not shown in the provided source.
- The “2026” paper dates and version history suggest this may be forward-dated or speculative; the sources do not clarify.
- Actual implementation details (how judges are spawned, how the rubric is weighted) are described at a conceptual level rather than shown in code.
Verdict Worth a look if you maintain more than a handful of Claude Code skills and have watched them drift out of sync with reality. Less useful if you treat prompts as write-once artifacts, or if you need fully hands-off automation — the human checkpoints are a deliberate design choice, not a missing feature.
Frequently asked
- What is alchaincyf/darwin-skill?
- Darwin.skill treats prompt engineering like model training: edit, score, revert if it regresses.
- Is darwin-skill open source?
- Yes — alchaincyf/darwin-skill is an open-source project tracked on heatdrop.
- What language is darwin-skill written in?
- alchaincyf/darwin-skill is primarily written in HTML.
- How popular is darwin-skill?
- alchaincyf/darwin-skill has 5k stars on GitHub and is currently accelerating.
- Where can I find darwin-skill?
- alchaincyf/darwin-skill is on GitHub at https://github.com/alchaincyf/darwin-skill.