aiming-lab/MetaClaw
Your agent that learns while you Slack
MetaClaw sits between you and your LLM, turning every chat into a training signal without killing your laptop.
Not currently ranked — collecting fresh signals.
star history
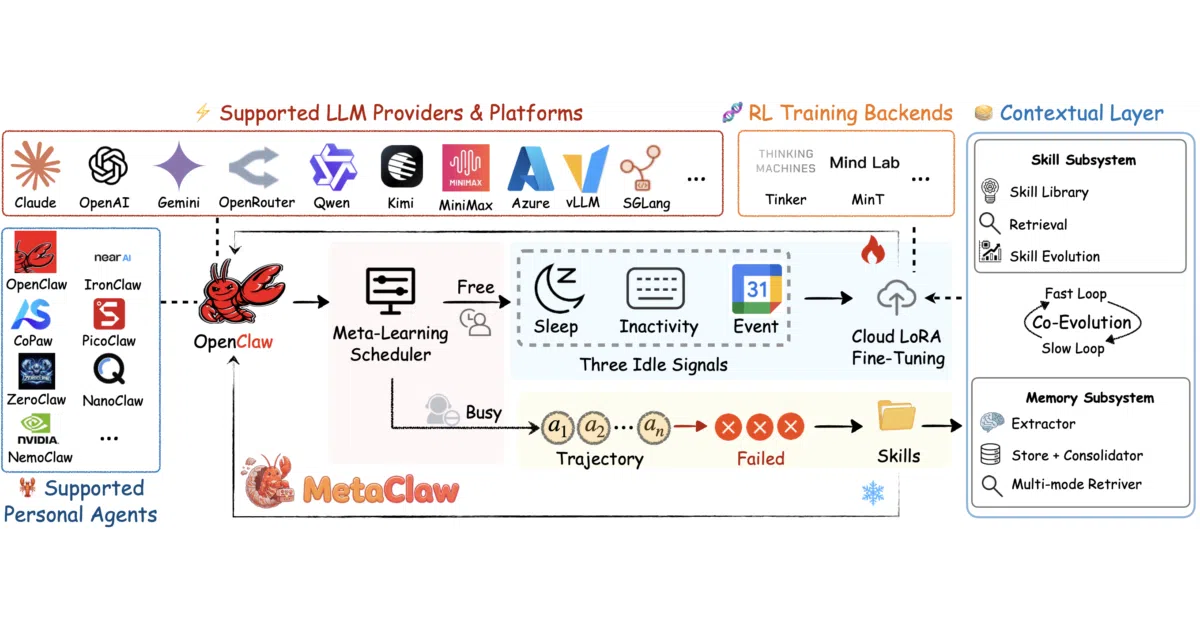
What it does MetaClaw is a transparent proxy for personal AI agents (OpenClaw, CoPaw, IronClaw, and five others). It intercepts your conversations, injects learned “skills” at each turn, and optionally runs reinforcement learning on the backend to evolve the model. You keep chatting normally; it keeps learning. No local GPU required — training happens via cloud LoRA services like Tinker, MinT, or Weaver.
The interesting bit The “auto” mode is the clever part: weight updates get deferred to when you’re asleep, idle, or stuck in a Google Calendar meeting. The agent never goes offline for training. The README also notes support/query set separation to keep stale rewards from poisoning model updates — a small detail that suggests someone actually thought about the continual-learning problem rather than just bolting RL onto a chatbot.
Key highlights
- Three modes:
skills_only(lightweight proxy),rl(immediate training), andauto(scheduled, default) - Long-term memory layer persists facts and project history across sessions, with incremental ingestion every N turns
- Fully async architecture: serving, reward modeling, and training run in parallel
- One-click setup via
metaclaw setup+metaclaw start; auto-configures your chosen agent - Anthropic-compatible
/v1/messagesendpoint for NanoClaw and other non-OpenAI-native agents
Caveats
- RL training requires third-party backends (Tinker, MinT, or Weaver) installed separately; the README is explicit that these are not bundled
- The “no GPU required” claim holds for the proxy/memory path, but RL mode still depends on external cloud training services with their own costs and availability
- v0.4.1 memory ingestion is incremental but still batched (default every 5 turns), so there’s a small blackout window mid-session
Verdict Worth a look if you’re already living in OpenClaw or similar agent frameworks and want your assistant to stop forgetting everything every session. Skip it if you just need a static LLM wrapper — the value is specifically in the continual-learning plumbing.
Frequently asked
- What is aiming-lab/MetaClaw?
- MetaClaw sits between you and your LLM, turning every chat into a training signal without killing your laptop.
- Is MetaClaw open source?
- Yes — aiming-lab/MetaClaw is open source, released under the MIT license.
- What language is MetaClaw written in?
- aiming-lab/MetaClaw is primarily written in Python.
- How popular is MetaClaw?
- aiming-lab/MetaClaw has 3.5k stars on GitHub.
- Where can I find MetaClaw?
- aiming-lab/MetaClaw is on GitHub at https://github.com/aiming-lab/MetaClaw.