VectifyAI/PageIndex
RAG inspired by AlphaGo: tree search over documents
PageIndex replaces vector similarity search with hierarchical tree reasoning to retrieve complex documents more accurately.
Velocity · 7d
+18
★ / day
Trend
↘cooling
star history
What it does
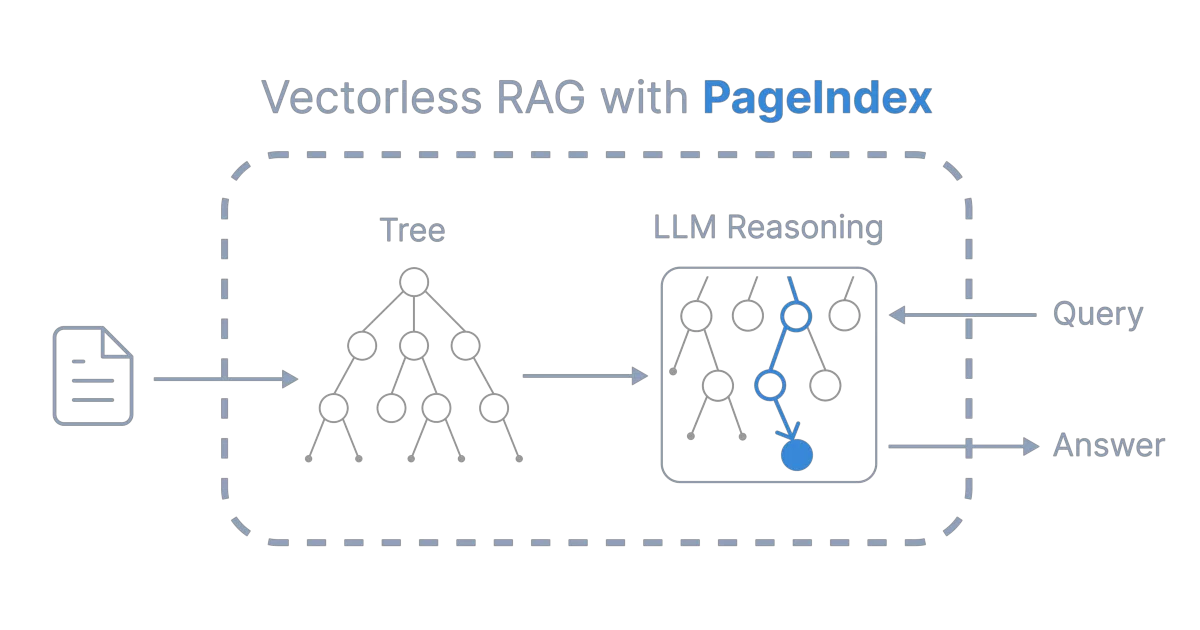
PageIndex ingests long documents—financial reports, legal filings, textbooks—and builds a hierarchical tree index resembling a table of contents. Instead of chunking text and querying a vector database for semantic similarity, it uses an LLM to navigate the tree and reason about which sections are actually relevant to your query. The open-source repo handles PDF and Markdown inputs, and there is a cloud tier with enhanced OCR for messier documents.
The interesting bit
The project explicitly rejects the “similarity equals relevance” assumption that underpins most RAG pipelines. By treating retrieval as a tree-search reasoning task—borrowing the AlphaGo analogy—it aims for explainability: you get page and section references back instead of opaque embedding distances. There is even a vision-based mode that works directly on page images without OCR.
Key highlights
- Vectorless retrieval: no embeddings, no chunking, no vector DB
- Hierarchical tree index generated from document structure with summaries and node IDs
- Reports 98.7% accuracy on FinanceBench via its reasoning-based approach
- Self-hostable with standard PDF parsing, or available as a cloud API/MCP with enhanced OCR
- Scales to millions of documents via a file-level PageIndex File System layer
Caveats
- The open-source version relies on standard PDF parsing; the README notes that complex PDFs may need the cloud service’s enhanced OCR
- Markdown support requires properly formatted heading hierarchies and is explicitly not recommended for PDF-converted Markdown files
- Tree generation and retrieval are LLM-driven, so latency and cost depend on model calls rather than a fast vector lookup
Verdict
Worth a look if you are building RAG over long, structured professional documents and are skeptical of embedding-based retrieval. Skip it if you need millisecond-scale retrieval on massive unstructured text corpora where vector search already works fine.
Frequently asked
- What is VectifyAI/PageIndex?
- PageIndex replaces vector similarity search with hierarchical tree reasoning to retrieve complex documents more accurately.
- Is PageIndex open source?
- Yes — VectifyAI/PageIndex is open source, released under the MIT license.
- What language is PageIndex written in?
- VectifyAI/PageIndex is primarily written in Python.
- How popular is PageIndex?
- VectifyAI/PageIndex has 34.2k stars on GitHub and is currently cooling off.
- Where can I find PageIndex?
- VectifyAI/PageIndex is on GitHub at https://github.com/VectifyAI/PageIndex.