Tiiny-AI/PowerInfer
Running 40B models on an RTX 4090 by sorting neurons by popularity
PowerInfer keeps frequently activated 'hot' neurons on your GPU and offloads the 'cold' ones to your CPU, letting a consumer RTX 4090 run 40B models at speeds the authors say are within 18% of an A100.
Not currently ranked — collecting fresh signals.
star history
What it does
PowerInfer is a CPU/GPU inference engine for serving large language models on a single consumer-grade GPU. It profiles which neurons are “hot”—activated by nearly every input—and preloads them into VRAM, while sending rarely triggered “cold” neurons to the CPU. This hybrid scheduling cuts GPU memory pressure and PCIe traffic, allowing models like Falcon-40B or OPT-175B to run on an RTX 4090.
The interesting bit
The core insight is that LLM activations follow a power-law distribution: a small fraction of parameters does most of the work. PowerInfer treats this as a caching problem, using adaptive predictors to guess which neurons will fire and moving the inactive bulk to system RAM, effectively turning weight sparsity into a GPU-CPU load-balancing act.
Key highlights
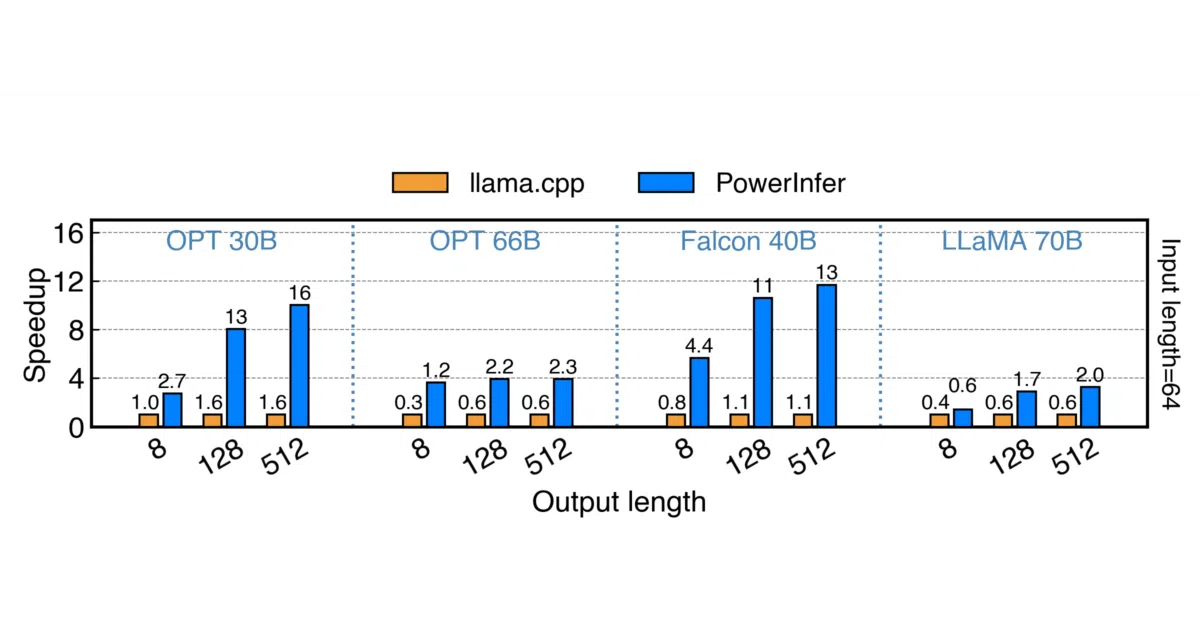
- Benchmarked at up to 11.69× faster than llama.cpp on an RTX 4090 (24 GB) when running Falcon(ReLU)-40B-FP16, with peak generation hitting 29.08 tokens/s
- Requires PowerInfer GGUF weights—which bundle predictor weights and activation profiles—or compatible ReLU-sparse models; standard dense llama.cpp checkpoints run but without performance gains
- Supports NVIDIA (CUDA) and AMD (ROCm) on Linux and Windows; an Apple Silicon macOS build exists but the README warns gains are “not significant now” and Metal sparse support is still pending
- Backward compatible with llama.cpp
examples/and model formats, so existing server and batched-generation setups mostly work out of the box - The same research group ships PowerInfer-2 for smartphones and TurboSparse models pushing ~90% sparsity, though those live in separate artifacts
Caveats
- You need specifically converted weights or sparse model variants to see the advertised speedups; dense models are supported for compatibility only
- macOS/Metal optimization is missing, so Apple Silicon users should not expect the dramatic gains seen on NVIDIA hardware
- Broader model support beyond Falcon, LLaMA-2, ProSparse, and Bamboo is not clearly documented
Verdict
A strong candidate if you own a consumer NVIDIA or AMD card and want to run 40B-class sparse models locally without cloud bills. If your workflow depends on standard dense checkpoints or you are on macOS, the benefits shrink considerably.
Frequently asked
- What is Tiiny-AI/PowerInfer?
- PowerInfer keeps frequently activated 'hot' neurons on your GPU and offloads the 'cold' ones to your CPU, letting a consumer RTX 4090 run 40B models at speeds the authors say are within 18% of an A100.
- Is PowerInfer open source?
- Yes — Tiiny-AI/PowerInfer is open source, released under the MIT license.
- What language is PowerInfer written in?
- Tiiny-AI/PowerInfer is primarily written in C++.
- How popular is PowerInfer?
- Tiiny-AI/PowerInfer has 9.7k stars on GitHub.
- Where can I find PowerInfer?
- Tiiny-AI/PowerInfer is on GitHub at https://github.com/Tiiny-AI/PowerInfer.