Tencent-Hunyuan/UniRL
Reinforcement learning that doesn't care if you generate pixels or tokens
One framework to run RL post-training on diffusion, autoregressive, and hybrid models without rewriting the orchestration layer each time.
Velocity · 7d
+4.3
★ / day
Trend
→steady
star history
What it does
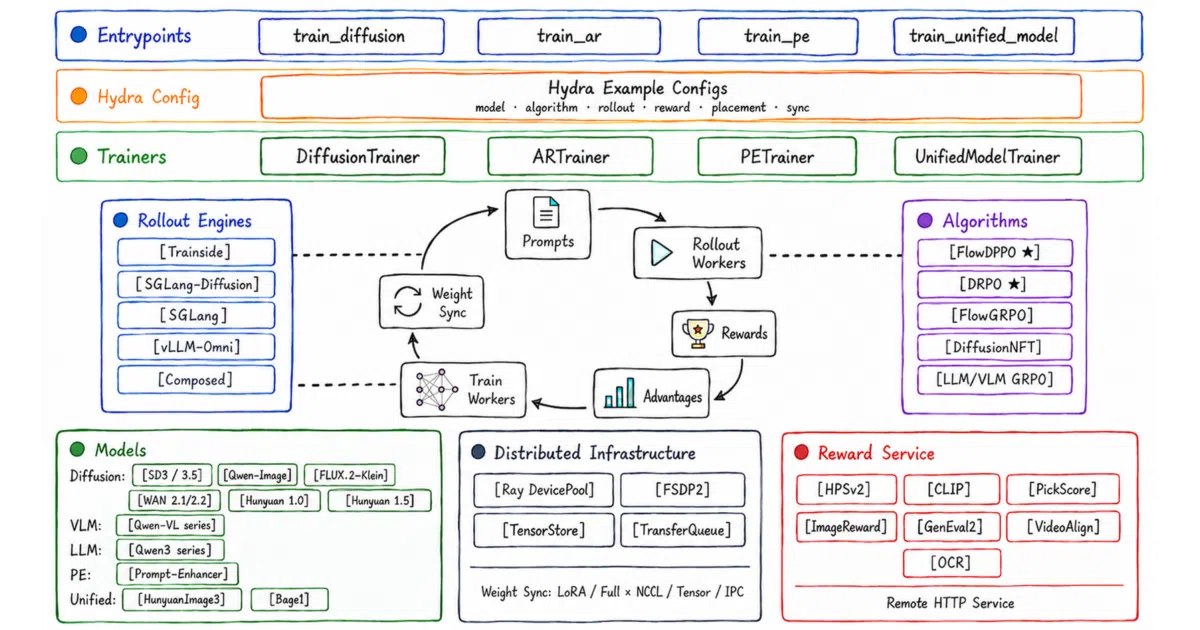
UniRL is a composable reinforcement-learning post-training framework that runs the same generate-score-update loop across wildly different model families: image and video diffusion, vision-language models, text LLMs, prompt enhancers, and unified AR-plus-diffusion hybrids. Each domain gets its own Hydra-configured entrypoint and trainer (train_diffusion, train_ar, train_pe, train_unified_model), but they all share a distributed runtime built on Ray, FSDP, and a Transfer Queue for weight sync.
The interesting bit
The framework treats model type and RL algorithm as independent dimensions within each domain, so any diffusion algorithm can run on any diffusion model and any AR algorithm on any AR model. That means a new method like Flow-DPPO or DRPO can be composed with the supported models in its domain without waiting for a bespoke integration.
Key highlights
- Ships with four domain entrypoints covering everything from Stable Diffusion 3 to Qwen3 to HunyuanVideo, each driven by a self-contained Hydra recipe.
- Includes the team’s own algorithms—Flow-DPPO for flow-matching models and DRPO for LLM divergence regularization—alongside reference implementations like GRPO and DiffusionNFT.
- Runtime is pluggable: swap rollout engines (vLLM, SGLang), reward services, and sync strategies (LoRA or full weights) through YAML configuration.
- Supports a wide model roster including FLUX.2-Klein, WAN 2.1/2.2, Qwen-VL, and unified models like HunyuanImage3 and Bagel.
Caveats
- Algorithm coverage for newer model families such as FLUX.2-Klein, HunyuanVideo 1.0/1.5, and Bagel is still expanding; the roadmap explicitly calls this out as near-term work.
Verdict
Teams training diffusion, LLM, or hybrid models who want a shared RL infrastructure rather than four separate pipelines should look here. If you only ever fine-tune one model family with a single fixed algorithm, the abstraction overhead may not pay rent.
Frequently asked
- What is Tencent-Hunyuan/UniRL?
- One framework to run RL post-training on diffusion, autoregressive, and hybrid models without rewriting the orchestration layer each time.
- Is UniRL open source?
- Yes — Tencent-Hunyuan/UniRL is an open-source project tracked on heatdrop.
- What language is UniRL written in?
- Tencent-Hunyuan/UniRL is primarily written in Python.
- How popular is UniRL?
- Tencent-Hunyuan/UniRL has 855 stars on GitHub and is currently holding steady.
- Where can I find UniRL?
- Tencent-Hunyuan/UniRL is on GitHub at https://github.com/Tencent-Hunyuan/UniRL.