Ryan-yang125/ChatLLM-Web
A ChatGPT clone that lives entirely in your tab
No server, no API keys, no data leaving your laptop—just a 4GB model download and a WebGPU-capable browser.
Not currently ranked — collecting fresh signals.
star history
What it does
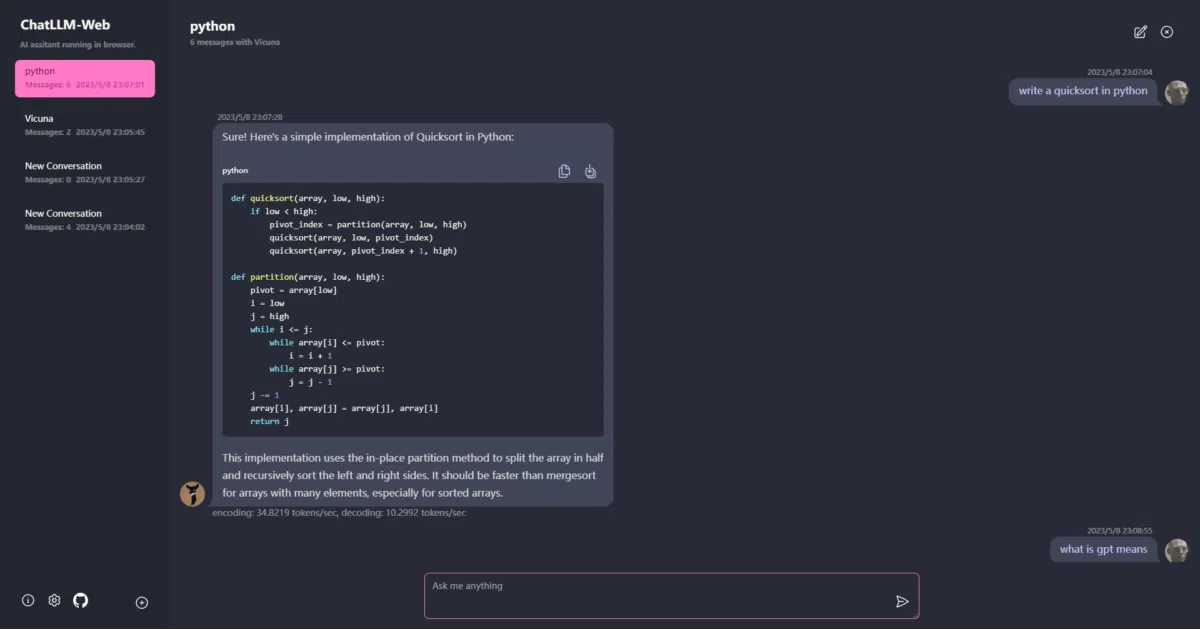
ChatLLM-Web is a browser-based chat interface for Vicuna-7B (with RedPajama-3B planned) built on top of MLC’s web-llm. It downloads the model once, caches it, and runs inference in a web worker so your UI doesn’t freeze. Multi-conversation history, markdown rendering, code highlighting, dark mode, and PWA offline support are all included.
The interesting bit
The heavy lifting isn’t this repo—it’s the deployment sugar. The author wrapped web-llm in a Next.js app with one-click Vercel deploy, model caching, and a polished mobile-responsive UI. Think of it as the reference “chat UI” that the underlying engine didn’t ship with.
Key highlights
- Runs 100% client-side; zero backend infrastructure to maintain or leak data to
- WebGPU acceleration via Chrome 113+ (6.4GB GPU memory recommended, though it degrades gracefully)
- PWA support means it works offline after first model download
- Web worker isolation keeps the chat responsive during token generation
- One-minute Vercel deploy with their button
Caveats
- Only Vicuna-7B is currently supported; the roadmap lists RedPajama-3B as unchecked
- Settings like temperature, max-length, and GPU device selection are on the roadmap but not yet implemented
- Requires a very recent Chrome and a decent GPU; Firefox and Safari users are out of luck for now
Verdict
Worth a look if you want a private, self-hosted ChatGPT alternative without wrangling Python environments or API billing. Skip it if you need model choice, fine-grained inference controls, or support for modest hardware today.
Frequently asked
- What is Ryan-yang125/ChatLLM-Web?
- No server, no API keys, no data leaving your laptop—just a 4GB model download and a WebGPU-capable browser.
- Is ChatLLM-Web open source?
- Yes — Ryan-yang125/ChatLLM-Web is open source, released under the MIT license.
- What language is ChatLLM-Web written in?
- Ryan-yang125/ChatLLM-Web is primarily written in JavaScript.
- How popular is ChatLLM-Web?
- Ryan-yang125/ChatLLM-Web has 630 stars on GitHub.
- Where can I find ChatLLM-Web?
- Ryan-yang125/ChatLLM-Web is on GitHub at https://github.com/Ryan-yang125/ChatLLM-Web.