RManLuo/reasoning-on-graphs
LLMs hallucinate on knowledge graphs too. This ICLR paper tries to fix that.
RoG forces language models to plan retrieval paths before answering, grounding their reasoning in actual graph structure instead of confabulated connections.
Not currently ranked — collecting fresh signals.
star history
What it does
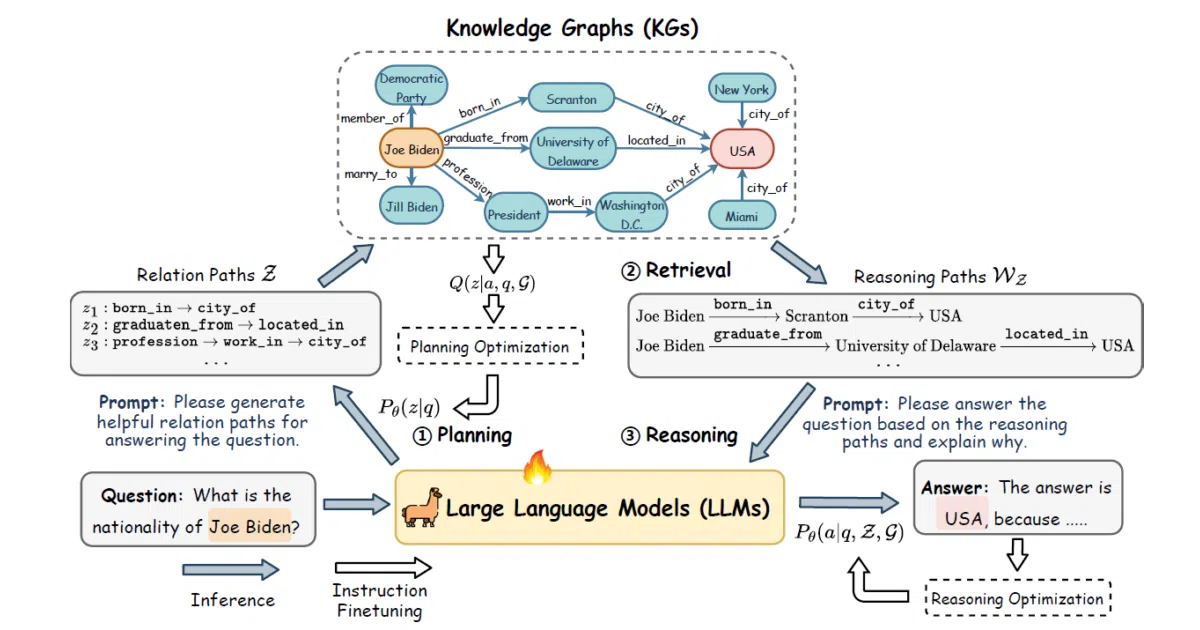
RoG is a framework that makes LLMs reason more honestly about knowledge graphs. It splits the work into three stages: first the model generates “relation paths” (think of them as query plans), then retrieves valid paths from the actual KG, then reasons over what it found. The hope is that the LLM can’t just make up edges that don’t exist.
The interesting bit
The planning step is the twist. Instead of letting the LLM freestyle through the graph, RoG makes it commit to a path structure upfront—grounded by the KG’s schema—then retrieves only valid instantiations. There’s also a plug-and-play mode where you can feed those same retrieved paths into GPT-3.5, Llama, or Flan-T5, suggesting the technique is more about the retrieval pipeline than a specific model architecture.
Key highlights
- Two-stage pipeline: plan relation paths, then retrieve and reason
- Pre-trained weights and datasets auto-download from HuggingFace
- Supports plug-and-play with multiple LLMs (GPT-3.5, Llama2, Alpaca, Flan-T5)
- Includes an interpretable reasoning script that shows the exact paths used
- Training requires 2× A100-80GB GPUs; inference needs 12GB VRAM
- ICLR 2024 paper with official implementation
Caveats
- The README doesn’t quantify the “faithfulness” gains—no specific accuracy deltas or hallucination rates are listed
- Training hardware requirements are steep (A100s), and the plug-and-play mode needs an OpenAI key set in a
.envfile, which is a small friction point - The authors have already moved on to newer work (GFM-RAG, Graph-constrained Reasoning), which may mean this repo is less actively maintained
Verdict
Worth a look if you’re building KG-QA systems and need interpretable reasoning traces, or if you’re researching LLM hallucination on structured knowledge. Skip if you want a lightweight, production-ready RAG system—this is research code with heavy training requirements and no stated latency or cost benchmarks.
Frequently asked
- What is RManLuo/reasoning-on-graphs?
- RoG forces language models to plan retrieval paths before answering, grounding their reasoning in actual graph structure instead of confabulated connections.
- Is reasoning-on-graphs open source?
- Yes — RManLuo/reasoning-on-graphs is open source, released under the MIT license.
- What language is reasoning-on-graphs written in?
- RManLuo/reasoning-on-graphs is primarily written in Python.
- How popular is reasoning-on-graphs?
- RManLuo/reasoning-on-graphs has 526 stars on GitHub.
- Where can I find reasoning-on-graphs?
- RManLuo/reasoning-on-graphs is on GitHub at https://github.com/RManLuo/reasoning-on-graphs.