QwenLM/Qwen3-VL
Alibaba's vision model now drives your phone and reads your screen
Qwen3-VL turns images and video into actionable instructions, with enough context window to swallow a book or hours of footage whole.
Velocity · 7d
+8.6
★ / day
Trend
↘cooling
star history
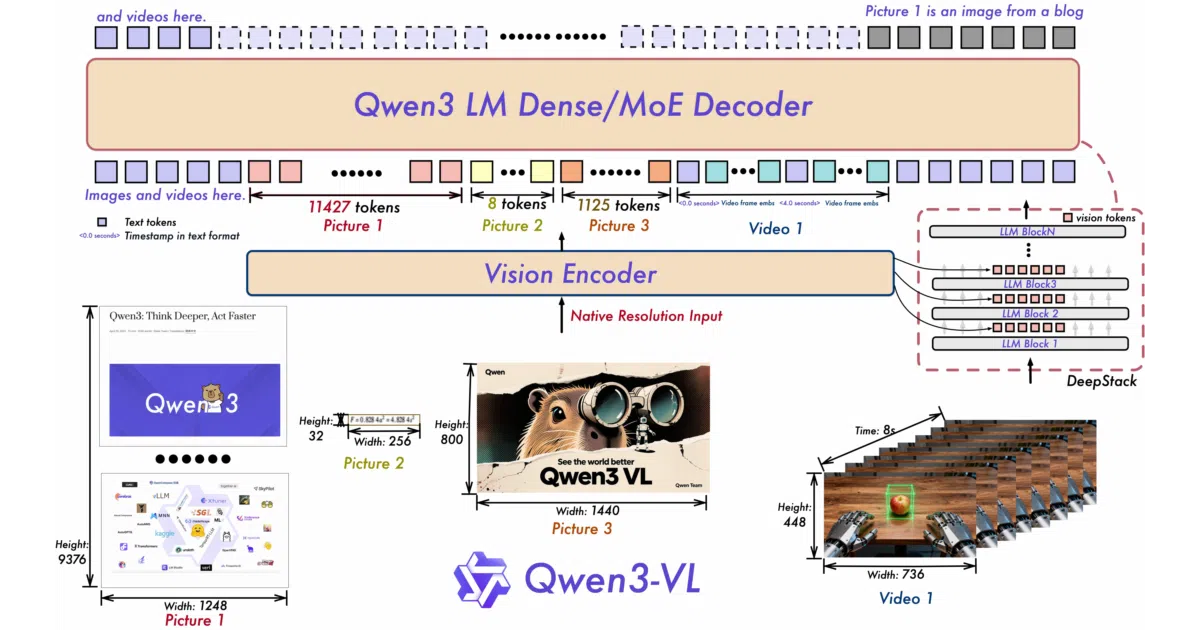
What it does Qwen3-VL is a family of vision-language models from Alibaba’s Qwen team that ingests images, video, and text, then reasons across all three. It comes in sizes from 2B to 235B parameters, in both dense and mixture-of-experts flavors, plus “Instruct” and “Thinking” variants depending on whether you want fast answers or chain-of-thought deliberation.
The interesting bit The model doubles as a visual agent: it can parse PC and mobile UIs, identify clickable elements, and execute tasks. The architecture tweaks are where the work lives—Interleaved-MRoPE encodes position across time, width, and height simultaneously, while DeepStack fuses multiple ViT feature levels so fine details don’t get washed out in early layers.
Key highlights
- Native 256K context, expandable to 1M tokens—enough for entire books or multi-hour video with second-level indexing
- Visual agent capabilities for GUI automation on both desktop and mobile
- 3D spatial grounding and embodied-AI reasoning, not just 2D bounding boxes
- OCR expanded to 32 languages, with claims of handling blur, tilt, and rare characters
- Generates Draw.io, HTML, CSS, and JS from visual inputs
- Cookbooks provided for recognition, document parsing, video understanding, and agent control
Caveats
- The repo itself is mostly documentation and cookbooks; model weights live on Hugging Face and ModelScope
- Fine-tuning code still points to the older Qwen2.5-VL repository
- Benchmark tables are presented as images without extractable numbers, so independent verification is awkward
Verdict Worth a look if you’re building multimodal agents, document pipelines, or video analysis tools and need a single model that spans edge devices to cloud GPUs. Skip if you want a lightweight, self-contained codebase—this is a model release with supporting notebooks, not a framework.
Frequently asked
- What is QwenLM/Qwen3-VL?
- Qwen3-VL turns images and video into actionable instructions, with enough context window to swallow a book or hours of footage whole.
- Is Qwen3-VL open source?
- Yes — QwenLM/Qwen3-VL is open source, released under the Apache-2.0 license.
- What language is Qwen3-VL written in?
- QwenLM/Qwen3-VL is primarily written in Jupyter Notebook.
- How popular is Qwen3-VL?
- QwenLM/Qwen3-VL has 19.6k stars on GitHub and is currently cooling off.
- Where can I find Qwen3-VL?
- QwenLM/Qwen3-VL is on GitHub at https://github.com/QwenLM/Qwen3-VL.