ParisNeo/lollms_hub
The Ollama Proxy With a Vision Hack and a Hierarchy
LoLLMs Hub wraps a fleet of Ollama, vLLM, and OpenAI-compatible backends into one key-secured API, adding hierarchical routing and a clever vision hack for text-only models.
Not currently ranked — collecting fresh signals.
star history
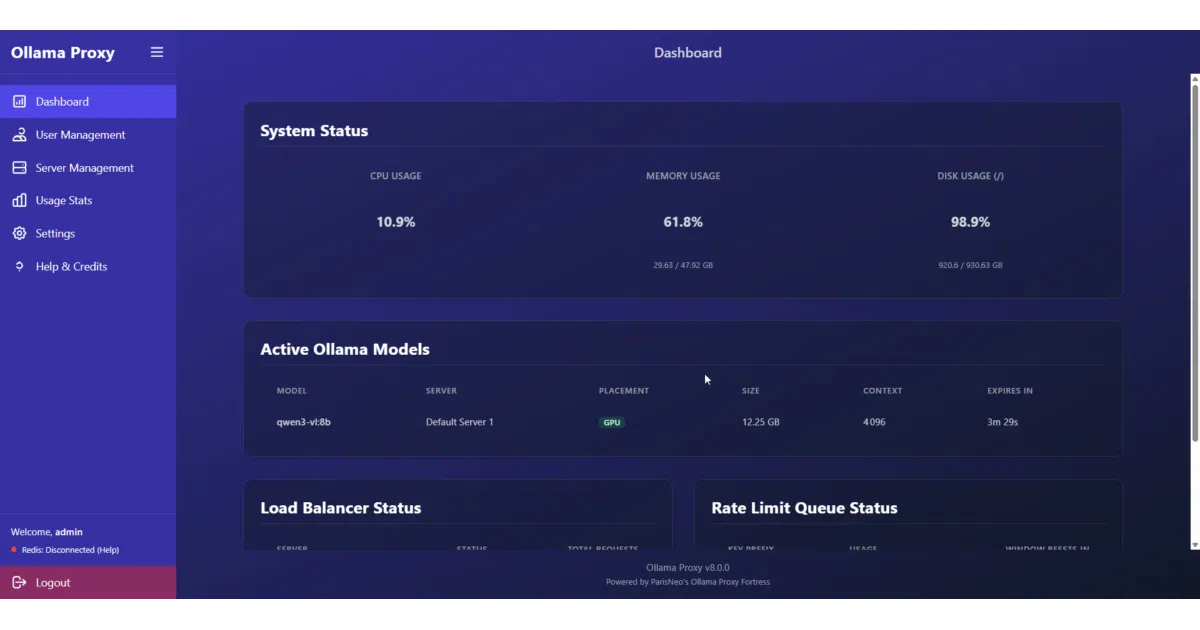
What it does LoLLMs Hub acts as a central API gateway for a scattered fleet of LLM inference engines. It fronts Ollama instances, vLLM clusters, llama.cpp servers, and OpenAI-compatible cloud endpoints with a single access point that handles keys, users, and rate limiting. The architecture is hierarchical: a master hub can delegate to slave hubs on worker machines, letting you keep raw GPU nodes off the public internet.
The interesting bit The standout feature is its routing logic. You can build “Smart Routers” that inspect prompts—checking for keywords, regex, image attachments, or even semantic intent via a small classifier model—to decide which backend handles the request. The slickest example is the vision enabler: it intercepts image uploads, routes them to a vision model for captioning, then forwards the text description plus original prompt to a text-only model that suddenly behaves like a VLM.
Key highlights
- Hierarchical master-slave clustering to simplify large or multi-machine deployments
- Load-balancing strategies including priority fallback, random distribution, and least-loaded routing
- Vision pipeline that pairs a VLM captioner with a text model to let text-only models handle image prompts by proxy
- Ensemble orchestration that dispatches prompts to multiple specialist models in parallel and synthesizes their outputs through a master model
- Built-in HTTPS/SSL termination, though the README notes a server restart is required to apply certificate changes
- Web UI for server management, user analytics, theming, and model pulling across nodes
Caveats
- The README promises “enterprise-grade security” and “extreme scale” without offering benchmarks or audit details, so take the fortress metaphors with a grain of salt.
- HTTPS certificate changes require a full server restart, which feels like a rough edge.
- The documentation contains duplicated step numbers in the visual showcase section, suggesting the project could use an editing pass.
Verdict Self-hosters running multiple Ollama boxes or mixing local and cloud APIs will appreciate the unified frontend and routing tricks. If you only have a single local model, this is overkill.
Frequently asked
- What is ParisNeo/lollms_hub?
- LoLLMs Hub wraps a fleet of Ollama, vLLM, and OpenAI-compatible backends into one key-secured API, adding hierarchical routing and a clever vision hack for text-only models.
- Is lollms_hub open source?
- Yes — ParisNeo/lollms_hub is open source, released under the Apache-2.0 license.
- What language is lollms_hub written in?
- ParisNeo/lollms_hub is primarily written in Python.
- How popular is lollms_hub?
- ParisNeo/lollms_hub has 640 stars on GitHub.
- Where can I find lollms_hub?
- ParisNeo/lollms_hub is on GitHub at https://github.com/ParisNeo/lollms_hub.