Paperspace/DataAugmentationForObjectDetection
Bounding boxes that survive a flip
Tutorial code that keeps your object detection labels honest through geometric augmentations.
Not currently ranked — collecting fresh signals.
star history
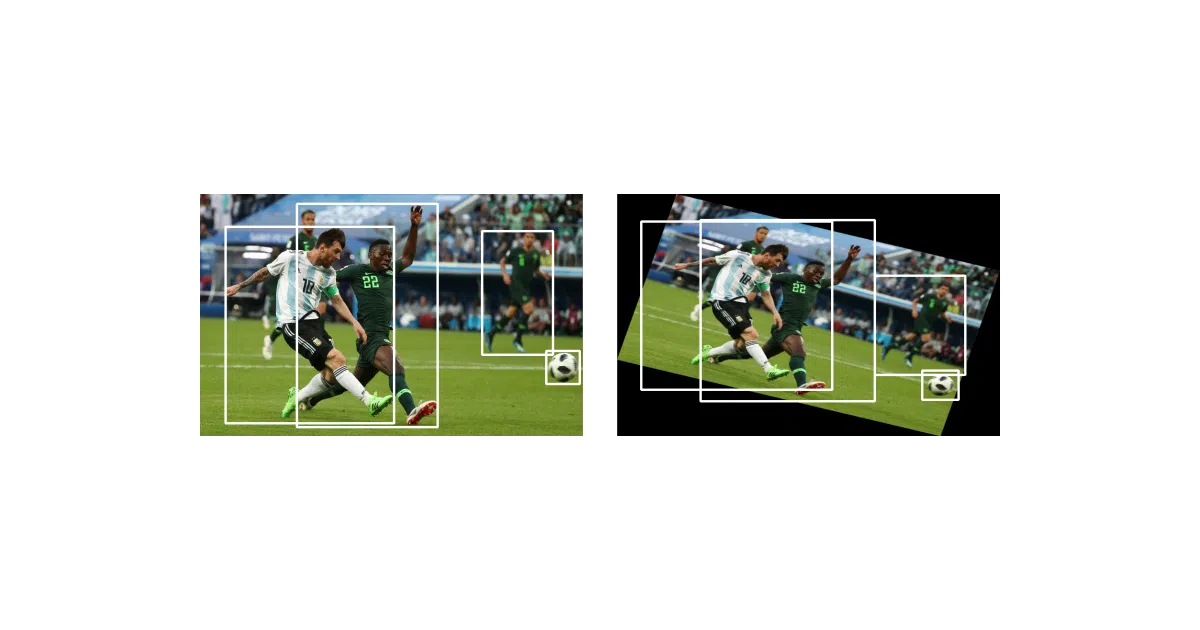
What it does This repo is the companion code for a Paperspace blog series on data augmentation for object detection. It implements transforms—flip, scale, translate, rotate, shear, resize—that update bounding box coordinates alongside the image pixels, so your labels don’t quietly lie to your model.
The interesting bit The hard part isn’t warping an image; it’s recalculating where the object actually ended up. The project treats bounding boxes as first-class citizens, not afterthoughts, which is rarer than it should be in augmentation libraries.
Key highlights
- Six core transforms: horizontal flip, scaling, translation, rotation, shearing, resizing
- Pure OpenCV + NumPy + Matplotlib; no heavy framework dependency
- Ships with a
quick-start.ipynbnotebook for immediate experimentation - Documentation hosted at
augmentationlib.paperspace.com - Directly tied to a detailed tutorial series, so the “why” is explained, not just the “how”
Caveats
- OpenCV 3.x is specified; compatibility with 4.x is unclear from the README
- The repo appears to be tutorial-grade code, not a maintained package—no install instructions or versioning mentioned
Verdict Worth a look if you’re building an object detection pipeline from scratch and want to understand augmentation mechanics. Skip it if you need a battle-hardened, pip-installable library like Albumentations.
Frequently asked
- What is Paperspace/DataAugmentationForObjectDetection?
- Tutorial code that keeps your object detection labels honest through geometric augmentations.
- Is DataAugmentationForObjectDetection open source?
- Yes — Paperspace/DataAugmentationForObjectDetection is open source, released under the MIT license.
- What language is DataAugmentationForObjectDetection written in?
- Paperspace/DataAugmentationForObjectDetection is primarily written in Jupyter Notebook.
- How popular is DataAugmentationForObjectDetection?
- Paperspace/DataAugmentationForObjectDetection has 1.2k stars on GitHub.
- Where can I find DataAugmentationForObjectDetection?
- Paperspace/DataAugmentationForObjectDetection is on GitHub at https://github.com/Paperspace/DataAugmentationForObjectDetection.