PRIME-RL/TTRL
When the test set is the training set
TTRL applies online reinforcement learning to reasoning problems whose correct answers are unknown, using majority voting across model rollouts as a proxy reward.
Not currently ranked — collecting fresh signals.
star history
What it does
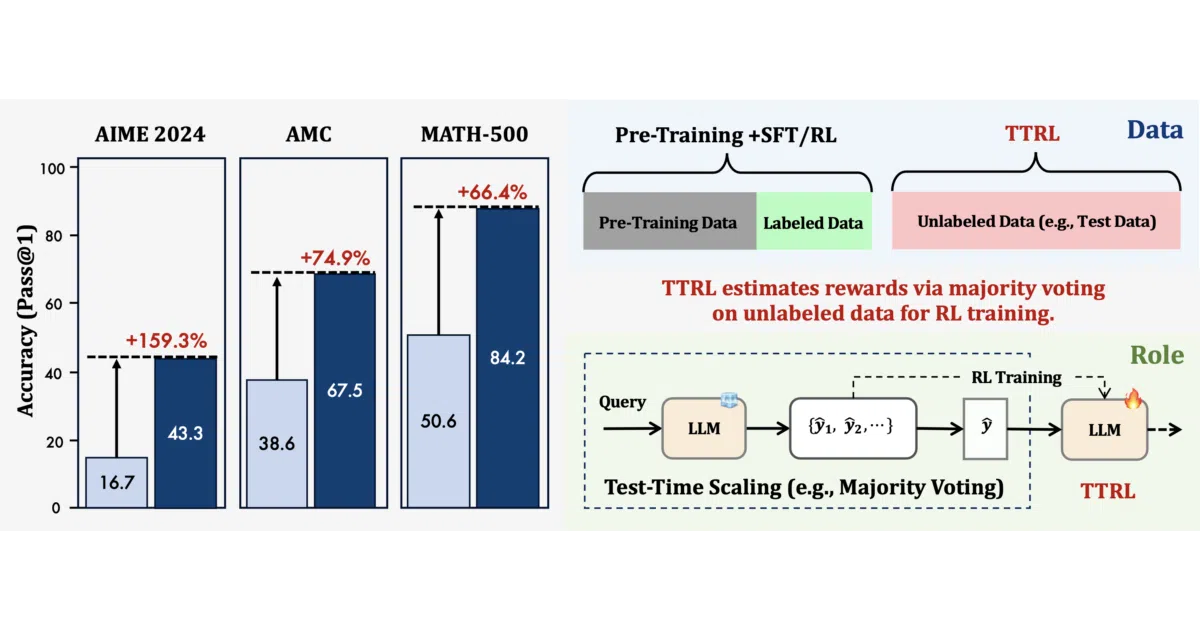
TTRL (Test-Time Reinforcement Learning) runs online RL on reasoning tasks when you have no ground-truth labels—exactly the situation you face with fresh test data. It generates multiple answers, treats the majority-vote consensus as a reward signal, and trains the model on its own unlabeled outputs. The implementation is built on top of the verl framework and can be enabled with a configuration flag.
The interesting bit
The core insight is that a crude majority-vote reward is strong enough to drive real improvement, consistently pushing past the initial model’s own majority-vote ceiling. On AIME 2024, the authors report roughly tripling the pass@1 score of a Qwen-2.5-Math-7B baseline using nothing but the test questions themselves.
Key highlights
- Uses
maj@n(majority voting) as a proxy reward when ground-truth answers are unavailable - Reportedly boosts Qwen-2.5-Math-7B
pass@1on AIME 2024 by about 211% using only unlabeled test data - Integrates into
verlv0.4.1 and can be toggled with+ttrl.enable=True - Achieves results approaching models trained directly on test data with true labels
- All reported experiments were run on 8× NVIDIA A100 80GB GPUs
Caveats
- The 43.3–46.7 greedy
pass@1scores were obtained with a preview version of the code, so the current release may behave differently - It is essentially a reward-function modification inside
verl; if you are not already using that stack, this is a plug-in rather than a standalone trainer
Verdict
Worth exploring if you have unlabeled reasoning benchmarks and a verl pipeline in place. Skip it if you need a fully independent training stack or are looking for methods that work on modest hardware.
Frequently asked
- What is PRIME-RL/TTRL?
- TTRL applies online reinforcement learning to reasoning problems whose correct answers are unknown, using majority voting across model rollouts as a proxy reward.
- Is TTRL open source?
- Yes — PRIME-RL/TTRL is open source, released under the MIT license.
- What language is TTRL written in?
- PRIME-RL/TTRL is primarily written in Python.
- How popular is TTRL?
- PRIME-RL/TTRL has 1.1k stars on GitHub.
- Where can I find TTRL?
- PRIME-RL/TTRL is on GitHub at https://github.com/PRIME-RL/TTRL.