OpenManus/OpenManus-RL
Live-streaming RL for agents: all theory, no results yet
A UIUC-MetaGPT collaboration applying DeepSeek-R1-style reinforcement learning to OpenManus agents, with progress broadcast in real time.
Not currently ranked — collecting fresh signals.
star history
What it does
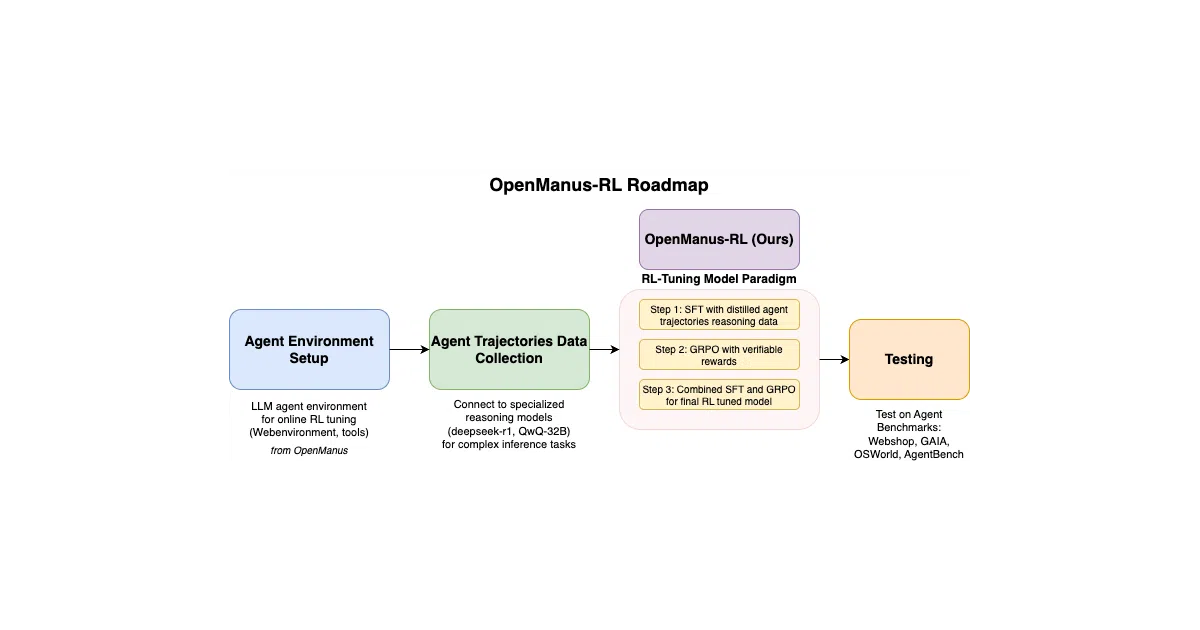
OpenManus-RL is a research effort to train LLM agents with reinforcement learning rather than simple prompting or supervised fine-tuning. It builds on the original OpenManus project and wraps ByteDance’s verl framework to experiment with PPO, GRPO, DPO and custom reward models. A curated dataset of ~50k agent trajectories—merged from AgentInstruct, Agent-FLAN and AgentGym—is already on Hugging Face.
The interesting bit The team is doing this in public: roadmap, half-built code and benchmark attempts all shared as they happen. That makes it unusually transparent for an academic-industrial collaboration, though it also means you are watching construction, not inspecting a finished house.
Key highlights
- Targets agent benchmarks: GAIA, AgentBench, WebShop, OSWorld
- Tests multiple rollout strategies: Tree-of-Thought, Graph-of-Thought, MCTS, DFSDT
- ReAct-format trajectories across OS, database, web, knowledge-graph, household and e-commerce tasks
verlintegrated as a git submodule for distributed RL training- Explicitly welcomes compute, data and codebase contributions; major contributors get paper co-authorship
Caveats
- The running code is described as “still laboriously developing” and the README asks for feedback, which suggests it is not yet fully functional
- No benchmark scores, trained model checkpoints or reproducible training recipes are published as of the README date
- Several sections are heavy on method descriptions (RICO-inspired, “sophisticated reward strategies”) but light on implementation specifics
Verdict Worth bookmarking if you are researching RL for tool-use agents and want to watch—or join—a live experiment. Skip it if you need a drop-in training pipeline or validated results today.
Frequently asked
- What is OpenManus/OpenManus-RL?
- A UIUC-MetaGPT collaboration applying DeepSeek-R1-style reinforcement learning to OpenManus agents, with progress broadcast in real time.
- Is OpenManus-RL open source?
- Yes — OpenManus/OpenManus-RL is open source, released under the Apache-2.0 license.
- What language is OpenManus-RL written in?
- OpenManus/OpenManus-RL is primarily written in Python.
- How popular is OpenManus-RL?
- OpenManus/OpenManus-RL has 4.1k stars on GitHub.
- Where can I find OpenManus-RL?
- OpenManus/OpenManus-RL is on GitHub at https://github.com/OpenManus/OpenManus-RL.