OpenGVLab/VisionLLM
Turning a language model into an open-ended vision decoder
VisionLLM v2 tries to handle hundreds of vision-language tasks—understanding, perception, and generation—through a single multimodal architecture.
Not currently ranked — collecting fresh signals.
star history
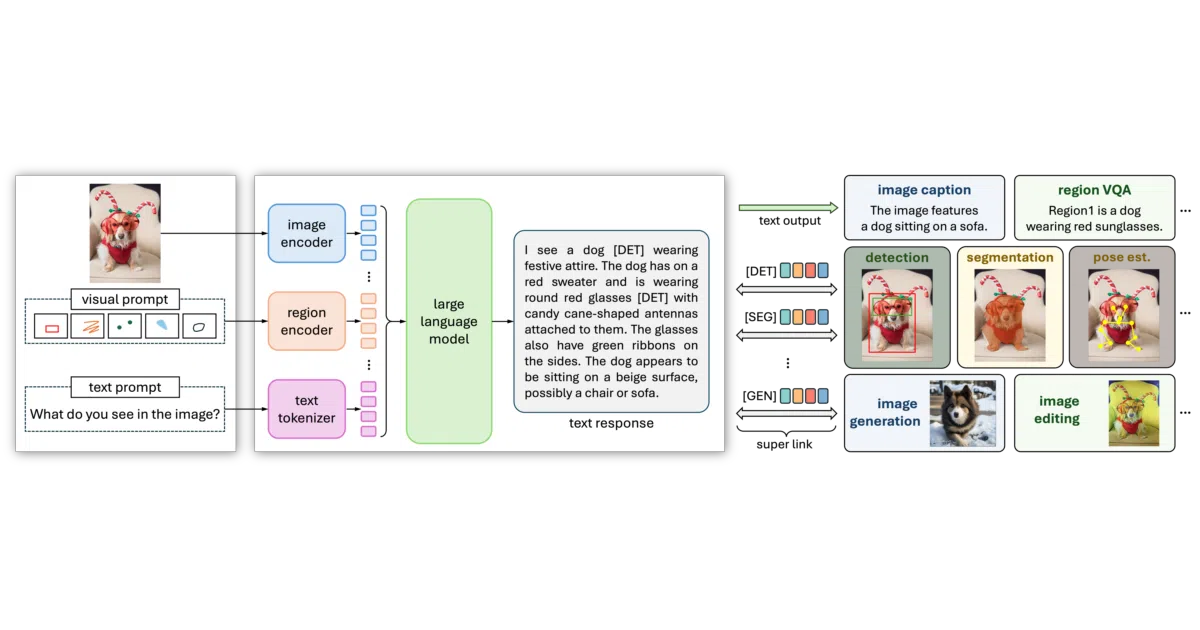
What it does VisionLLM is a research series that treats a large language model as an open-ended decoder for vision-centric tasks. VisionLLM v2, published at NeurIPS 2024, claims to generalize across hundreds of vision-language tasks spanning visual understanding, perception, and generation. The repository currently functions more as a paper index than a documented codebase.
The interesting bit Instead of using an LLM merely to caption images, the project uses it as the actual decoding backbone for visual tasks. That architectural choice—an LLM as vision decoder rather than just chat wrapper—is what separates it from the usual multimodal chatbot stack.
Key highlights
- Two iterations: the original VisionLLM (NeurIPS 2023) and VisionLLM v2 (NeurIPS 2024).
- v2 targets hundreds of vision-language tasks within one generalist model.
- Covers the full triad: visual understanding, perception, and generation.
- 1,148 stars, suggesting the research is drawing attention despite the bare-bones README.
Caveats
- The README is extremely sparse; it provides no code, benchmarks, or usage details beyond paper links and an architecture diagram.
- It is unclear from the sources what is actually runnable or downloadable in the repository.
Verdict Bookmark this if you are researching generalist multimodal architectures or tracking NeurIPS vision-language work. Look elsewhere if you need ready-to-run code or detailed documentation today.
Frequently asked
- What is OpenGVLab/VisionLLM?
- VisionLLM v2 tries to handle hundreds of vision-language tasks—understanding, perception, and generation—through a single multimodal architecture.
- Is VisionLLM open source?
- Yes — OpenGVLab/VisionLLM is open source, released under the Apache-2.0 license.
- What language is VisionLLM written in?
- OpenGVLab/VisionLLM is primarily written in Python.
- How popular is VisionLLM?
- OpenGVLab/VisionLLM has 1.2k stars on GitHub.
- Where can I find VisionLLM?
- OpenGVLab/VisionLLM is on GitHub at https://github.com/OpenGVLab/VisionLLM.