OpenGVLab/InternVideo
One repo, five video model generations, and a 230M-pair dataset
Shanghai AI Lab uses this monorepo as a rolling archive for its InternVideo dynasty—five generations of video foundation models, distilled variants, chat-tuned MLLMs, and the 230-million-pair InternVid dataset.
Not currently ranked — collecting fresh signals.
star history
What it does
The repository collects the InternVideo model family—InternVideo1 through InternVideo-Next—alongside the InternVid dataset and video instruction data for dialogue systems like VideoChat. It serves as the release hub for weights, technical reports, and annotations from Shanghai AI Lab’s General Vision Group.
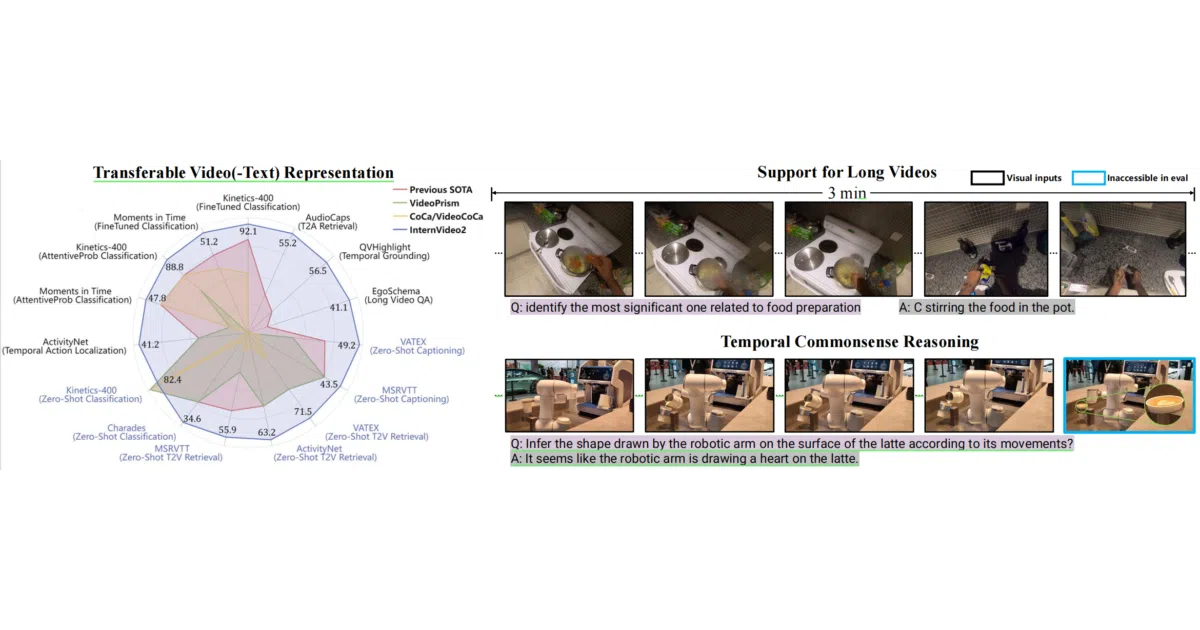
The interesting bit Instead of deprecating old releases, the team keeps every generation alive in subdirectories, turning the repo into a stratified archive of how video foundation models have evolved from basic generative pretraining to long-horizon agentic reasoning. The README reads like a research timeline, with releases stretching from 2022 to 2025 and model sizes ranging from distilled small variants up to 8B-parameter chat-tuned versions.
Key highlights
- Bundles five distinct model generations—
InternVideo1throughInternVideo-Next—in a single monorepo. - Includes
InternVid, a video-text dataset with 230 million annotated pairs, accepted as an ICLR 2024 spotlight. - Provides distilled smaller variants (
InternVideo2-S/B/L) and an 8B-parameter chat model (InternVideo2-Stage3-8B) built from a 1B video encoder and a 7B LLM. - Distributes weights and technical reports via HuggingFace alongside the code.
- Ships video instruction data for tuning end-to-end video-centric multimodal dialogue systems.
Caveats
- The README is essentially an index page and changelog; it offers almost no detail on architecture, training recipes, or comparative benchmarks. You will need to dig into individual subdirectories and linked technical reports to understand what actually changed between generations.
Verdict Worth cloning if you are researching video-language pretraining or need pretrained weights for multimodal video tasks. Look elsewhere if you want a single, well-documented framework with a clean API—this is a research artifact collection, not a library.
Frequently asked
- What is OpenGVLab/InternVideo?
- Shanghai AI Lab uses this monorepo as a rolling archive for its InternVideo dynasty—five generations of video foundation models, distilled variants, chat-tuned MLLMs, and the 230-million-pair InternVid dataset.
- Is InternVideo open source?
- Yes — OpenGVLab/InternVideo is open source, released under the Apache-2.0 license.
- What language is InternVideo written in?
- OpenGVLab/InternVideo is primarily written in Python.
- How popular is InternVideo?
- OpenGVLab/InternVideo has 2.3k stars on GitHub.
- Where can I find InternVideo?
- OpenGVLab/InternVideo is on GitHub at https://github.com/OpenGVLab/InternVideo.