OAID/AutoKernel
Auto-tuning deep-learning kernels without losing your mind
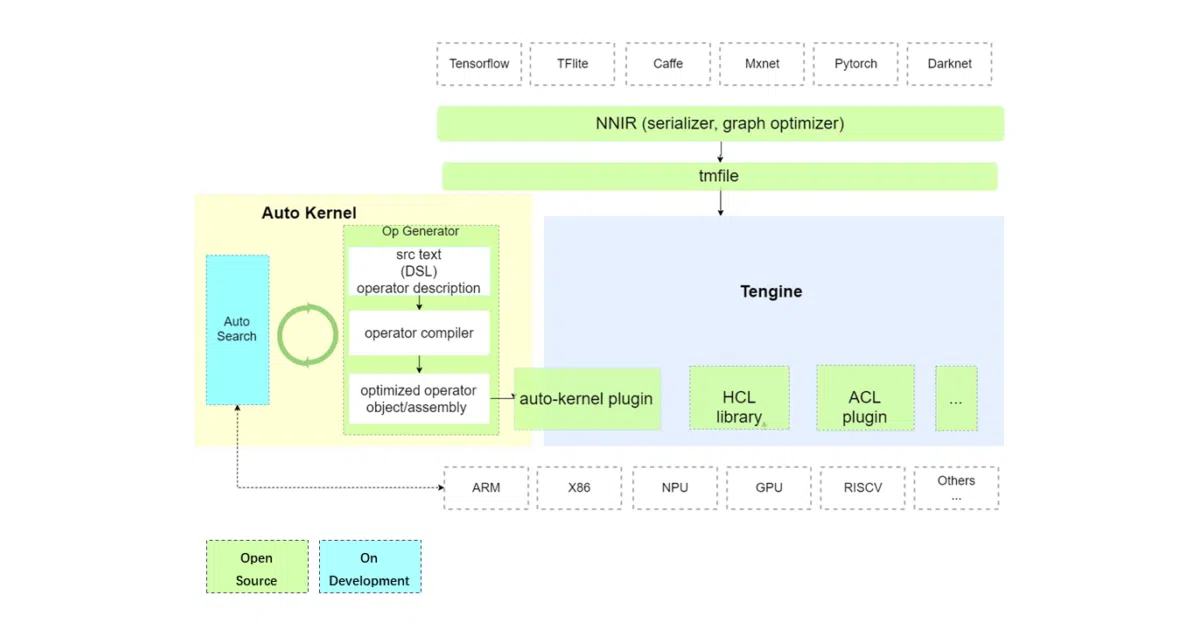
AutoKernel uses Halide's schedule separation plus search algorithms to generate optimized low-level operators for different hardware, then plugs them into Tengine.
Not currently ranked — collecting fresh signals.
star history
What it does AutoKernel generates high-performance low-level code for deep-learning operators across CPU, GPU, and specialized accelerators. It wraps Halide’s DSL to separate algorithm description from execution schedule, then searches for the best schedule using greedy algorithms, reinforcement learning, and other methods. The generated code drops into Tengine via a plugin without touching Tengine’s core.
The interesting bit The project treats operator optimization as a search problem rather than a craftsmanship problem. Halide already decouples what to compute from how to schedule it; AutoKernel adds automated search on top, which is the part that normally requires engineers with deep hardware knowledge and a lot of patience.
Key highlights
- Built on Halide’s proven DSL for separating algorithms from schedules
- AutoSearch module supports CPU and GPU targets, x86 and ARM
- One-click plugin integration with Tengine inference framework
- Docker images provided with Halide and Tengine pre-installed (CPU, CUDA, OpenCL)
- Apache 2.0 licensed, originated from OPEN AI LAB research
Caveats
- AutoSearch module is explicitly noted as “still under developping” [sic]
- README is light on concrete benchmarks or comparison numbers versus hand-optimized kernels
- 745 stars suggests limited production battle-testing so far
Verdict Worth a look if you’re deploying on Tengine and tired of hand-optimizing operators for each hardware target. Probably premature if you need mature, well-documented auto-scheduling today—TVM’s Ansor or Halide’s own autoscheduler may be further along.
Frequently asked
- What is OAID/AutoKernel?
- AutoKernel uses Halide's schedule separation plus search algorithms to generate optimized low-level operators for different hardware, then plugs them into Tengine.
- Is AutoKernel open source?
- Yes — OAID/AutoKernel is open source, released under the Apache-2.0 license.
- What language is AutoKernel written in?
- OAID/AutoKernel is primarily written in C++.
- How popular is AutoKernel?
- OAID/AutoKernel has 748 stars on GitHub.
- Where can I find AutoKernel?
- OAID/AutoKernel is on GitHub at https://github.com/OAID/AutoKernel.