NeymarL/ChineseChess-AlphaZero
AlphaZero learns Xiangqi, the hard way
A distributed effort to grow a Chinese-chess engine from random self-play, no human games required.
Not currently ranked — collecting fresh signals.
star history
What it does
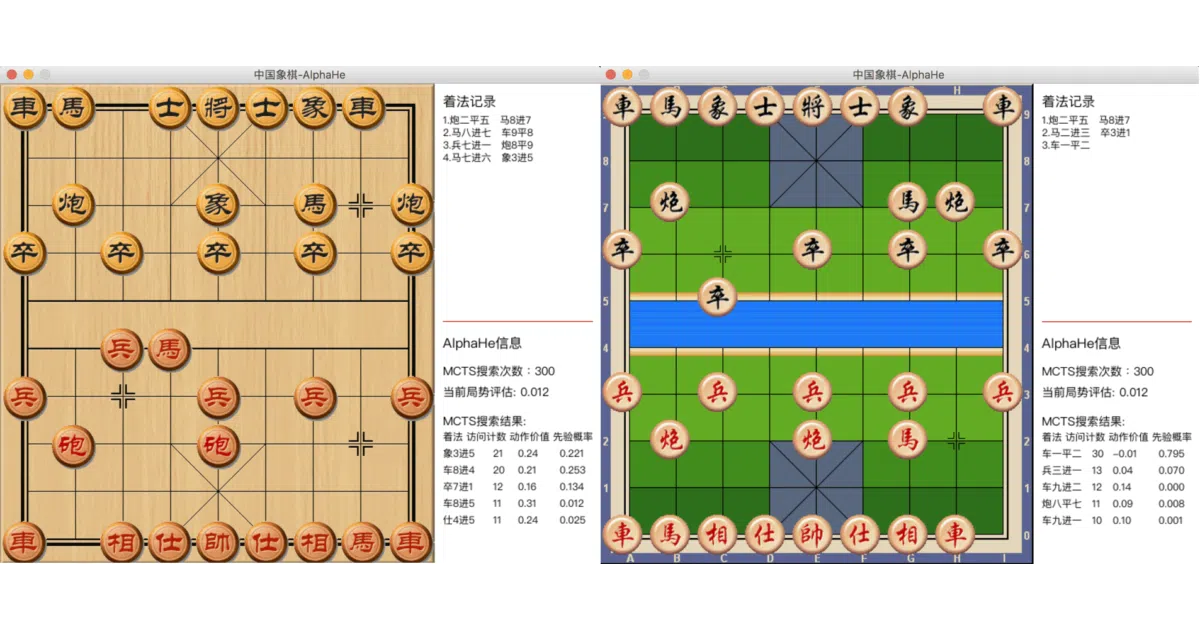
CCZero is an AlphaZero-style reinforcement-learning pipeline for Chinese chess (Xiangqi). It runs self-play games, trains neural nets on the results, and pits new models against the current champion in an endless loop. There is also a built-in pygame GUI so you can lose to the machine in style.
The interesting bit
The project is deliberately a distributed volunteer effort — the README openly admits you need “a huge amount of computations” and asks strangers to run self and opt workers to feed a central model pool. It is essentially SETI@home, but for training a board-game engine.
Key highlights
- Four worker types:
self(self-play),opt(training),eval(model vs. model), andsl(supervised warm-start from internet game databases) - Supports both UCI engine mode and a built-in GUI with swappable piece/board themes (WOOD, QIANHONG, SKELETON, etc.)
- Distributed mode uploads play data and downloads the latest model automatically
- TensorBoard logging and ELO tracking via https://cczero.org
- Windows executables available for non-developers
Caveats
- Stuck on a very specific legacy stack: Python 3.6.3, TensorFlow-GPU 1.3.0, Keras 2.0.8
- You must manually source a
PingFang.ttcfont file before the GUI will run; the author removed it for size - The README is thorough but reads like a wiki dump; finding the right
--typeflag for distributed training takes patience
Verdict
Worth a look if you want to study AlphaZero mechanics on a smaller, more tractable game than Go, or if you have spare GPU cycles and a fondness for Xiangqi. Everyone else should probably use a modern Leela Chess Zero derivative instead.
Frequently asked
- What is NeymarL/ChineseChess-AlphaZero?
- A distributed effort to grow a Chinese-chess engine from random self-play, no human games required.
- Is ChineseChess-AlphaZero open source?
- Yes — NeymarL/ChineseChess-AlphaZero is open source, released under the GPL-3.0 license.
- What language is ChineseChess-AlphaZero written in?
- NeymarL/ChineseChess-AlphaZero is primarily written in Python.
- How popular is ChineseChess-AlphaZero?
- NeymarL/ChineseChess-AlphaZero has 1.2k stars on GitHub.
- Where can I find ChineseChess-AlphaZero?
- NeymarL/ChineseChess-AlphaZero is on GitHub at https://github.com/NeymarL/ChineseChess-AlphaZero.