NanoNets/docext
An on-prem document toolkit that skips OCR and keeps score
Built to run OCR-free document extraction and markdown conversion on-prem, then benchmark which vision-language models are actually worth the GPU cycles.
Not currently ranked — collecting fresh signals.
star history
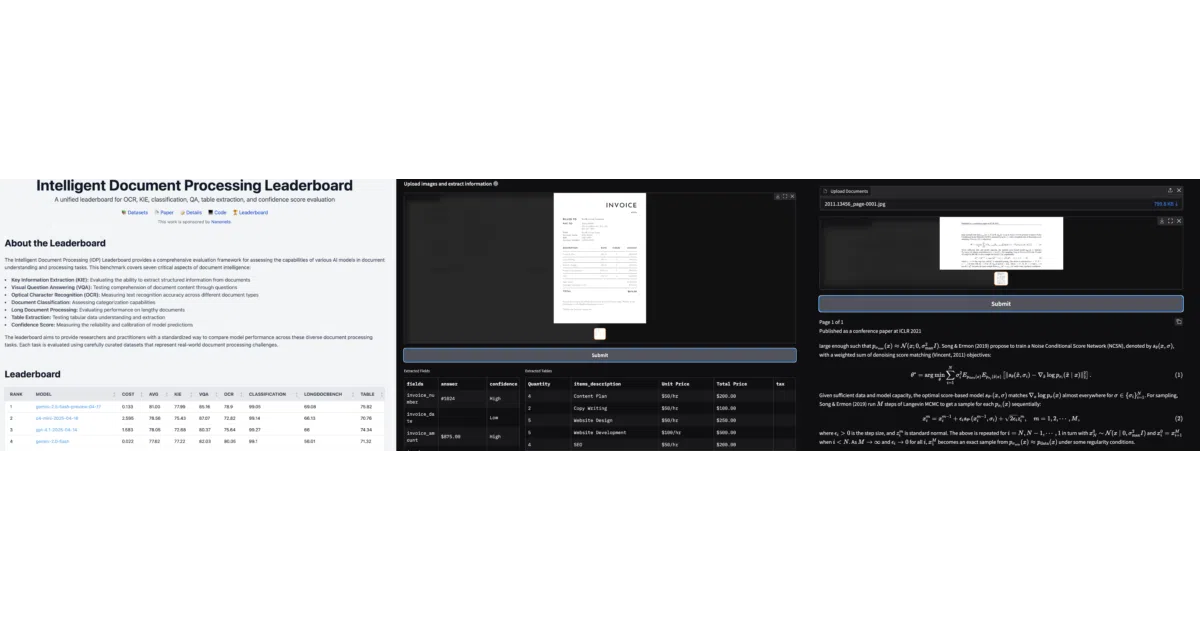
What it does
docext is an on-premises toolkit that uses vision-language models to pull structured data from documents and turn PDFs or images into semantic markdown. It handles invoices, passports, tables, LaTeX equations, signatures, and watermarks, wrapping each element in specific markup like <signature> tags or HTML tables. The same repository also powers a live benchmarking leaderboard that evaluates VLMs on tasks from key information extraction to confidence calibration.
The interesting bit
Instead of chaining traditional OCR pipelines, the markdown converter uses a dedicated compact 3B-parameter model, Nanonets-OCR-s, trained to recognize LaTeX, signatures, watermarks, and even render checkboxes as Unicode. Meanwhile, the bundled extraction tools and live leaderboard let you run the whole pipeline on-prem and compare how various VLMs—Gemini, Claude, Qwen, and others—stack up on real document tasks.
Key highlights
- OCR-free extraction with pre-built templates for invoices and passports, plus custom field definitions
- PDF-to-markdown conversion that preserves LaTeX, renders tables as HTML, and applies semantic tags for signatures, watermarks, and page numbers
- On-premises deployment via REST API on Linux and macOS, with multi-page document support
- Confidence scoring for extracted fields and structured tabular data
- Live IDP leaderboard tracking VLM performance across OCR, KIE, VQA, long-document reasoning, and table extraction
Verdict
Worth a look if you need to process sensitive documents locally without cloud OCR services, or if you are choosing a VLM and want hard benchmark numbers rather than marketing claims. Less useful if you are looking for a lightweight, traditional OCR-only pipeline.
Frequently asked
- What is NanoNets/docext?
- Built to run OCR-free document extraction and markdown conversion on-prem, then benchmark which vision-language models are actually worth the GPU cycles.
- Is docext open source?
- Yes — NanoNets/docext is open source, released under the Apache-2.0 license.
- What language is docext written in?
- NanoNets/docext is primarily written in Python.
- How popular is docext?
- NanoNets/docext has 2k stars on GitHub.
- Where can I find docext?
- NanoNets/docext is on GitHub at https://github.com/NanoNets/docext.