NVIDIA/cutlass
NVIDIA's matrix-math kitchen now speaks Python
CUTLASS 4.5 adds a Python DSL so you can write GPU kernels that hit peak Tensor Core throughput without wrestling C++ templates.
Velocity · 7d
+5.9
★ / day
Trend
→steady
star history
What it does
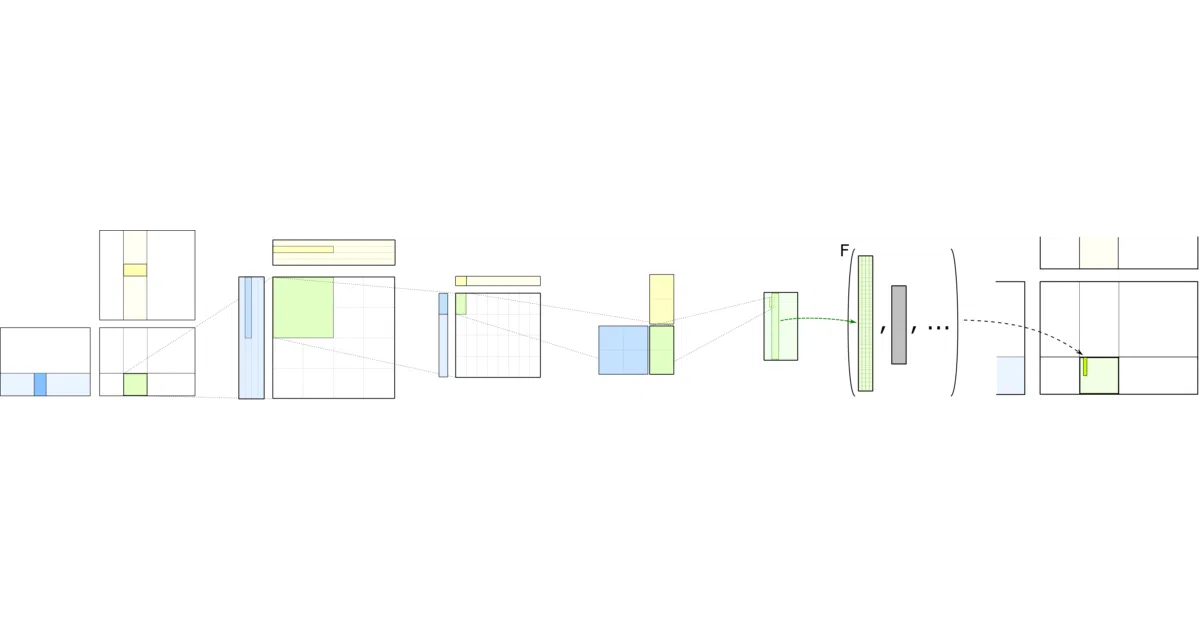
CUTLASS is NVIDIA’s long-running collection of C++ template abstractions for high-performance matrix multiplication (GEMM) and related linear algebra on CUDA GPUs. It handles the gnarly details of data movement, tiling, and Tensor Core instruction scheduling across Volta through Blackwell architectures. CUTLASS 4.x layers on a Python DSL — CuTe DSL — that exposes the same low-level control (layouts, tensors, hardware atoms, thread hierarchies) with faster compile times and native framework integration.
The interesting bit
The DSL isn’t a dumbed-down wrapper; it’s a genuine alternative frontend to the same CuTe abstractions, designed for metaprogramming without “deep C++ expertise.” The project explicitly targets students and researchers who need to prototype kernel designs quickly, then ship them to production without rewriting in C++. Also, someone named a neural-network activation function “Snake” and it’s now in the codebase.
Key highlights
- Supports an almost comically wide range of numeric formats: FP64 down to 1-bit binary, plus block-scaled types like NVFP4 and MXFP8/6/4
- CuTe DSL is in public beta (targeting graduation from beta by end of summer 2025)
- New
block_copy()API in 4.5 hides TMA multicast and 2CTA partition complexity - Mixed-precision MoE grouped-GEMM examples show speedups vs. PyTorch on B200 (up to ~1.4x for some MXFP8 configs)
- Windows builds are currently broken for all CUDA toolkits in 4.x
Caveats
- CuTe DSL is still beta; the C++ path remains the mature, fully supported option
- CUTLASS 4.x builds are known to fail on Windows for all CUDA toolkit versions
- The README’s performance charts reference CUTLASS 3.8 and 3.5.1, not the current 4.5.2 release
Verdict Performance engineers and researchers working on NVIDIA GPUs who need custom kernels but want to escape C++ template hell should investigate the DSL path. If you’re on Windows or need battle-tested stability today, stick with the C++ templates or wait for the DSL to exit beta.
Frequently asked
- What is NVIDIA/cutlass?
- CUTLASS 4.5 adds a Python DSL so you can write GPU kernels that hit peak Tensor Core throughput without wrestling C++ templates.
- Is cutlass open source?
- Yes — NVIDIA/cutlass is an open-source project tracked on heatdrop.
- What language is cutlass written in?
- NVIDIA/cutlass is primarily written in C++.
- How popular is cutlass?
- NVIDIA/cutlass has 10.1k stars on GitHub and is currently holding steady.
- Where can I find cutlass?
- NVIDIA/cutlass is on GitHub at https://github.com/NVIDIA/cutlass.