NVIDIA/TensorRT-LLM
NVIDIA's answer to 'why is my GPU not at 100%?'
A Pythonic framework and runtime that squeezes inference throughput out of NVIDIA GPUs for LLMs and visual-generation models.
Velocity · 7d
+7.3
★ / day
Trend
↘cooling
star history
What it does
TensorRT LLM is NVIDIA’s open-source inference stack for large language and visual-generation models. It gives you a Python API to define models, then dispatches to specialized CUDA kernels and an efficient C++ runtime so inference doesn’t waste cycles on generic ops. The project moved to fully open-source development on GitHub in March 2025.
The interesting bit
Instead of treating your GPU like a black box, the framework exposes a steady stream of hardware-specific optimizations—speculative decoding, sparse attention, skip-softmax kernels, and MoE-specific NVLink tricks—that are tightly coupled to new silicon like Blackwell. It recently added diffusion-model support, so it is no longer just a text shop.
Key highlights
- Day-0 support for recent major models including Llama 4, DeepSeek-R1, GPT-OSS, and EXAONE 4.0
- Targets both datacenter and edge deployment, with a dedicated branch for Jetson AGX Orin
- Heavy focus on MoE (Mixture of Experts) parallelism, KV-cache reuse, and disaggregated serving
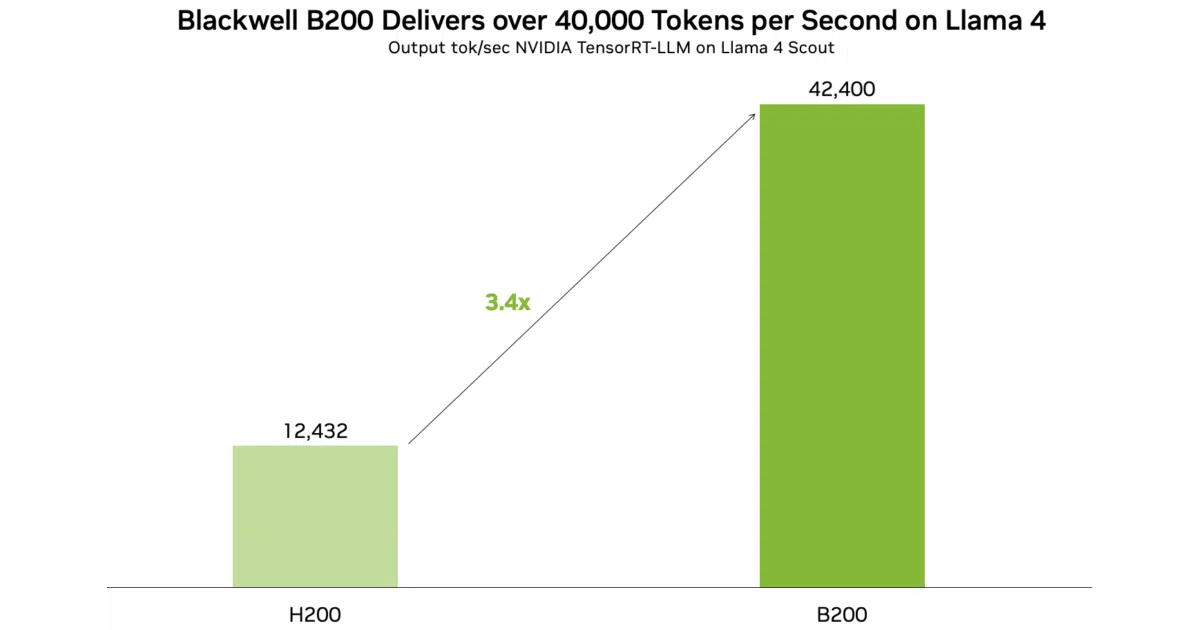
- Claims throughput north of 40,000 tokens/sec on B200 GPUs for Llama 4, per its own news section
- Requires specific dependency versions: Python 3.10 or 3.12, CUDA 13.1.1, PyTorch 2.10.0
Verdict
Worth a look if you are already committed to NVIDIA hardware and need to push inference throughput for LLMs or diffusion models. Everyone else—especially those on AMD, Intel, or Apple silicon—can safely keep scrolling.
Frequently asked
- What is NVIDIA/TensorRT-LLM?
- A Pythonic framework and runtime that squeezes inference throughput out of NVIDIA GPUs for LLMs and visual-generation models.
- Is TensorRT-LLM open source?
- Yes — NVIDIA/TensorRT-LLM is an open-source project tracked on heatdrop.
- What language is TensorRT-LLM written in?
- NVIDIA/TensorRT-LLM is primarily written in Python.
- How popular is TensorRT-LLM?
- NVIDIA/TensorRT-LLM has 14.2k stars on GitHub and is currently cooling off.
- Where can I find TensorRT-LLM?
- NVIDIA/TensorRT-LLM is on GitHub at https://github.com/NVIDIA/TensorRT-LLM.