Muennighoff/sgpt
GPT as an embedding engine, not just a chatbot
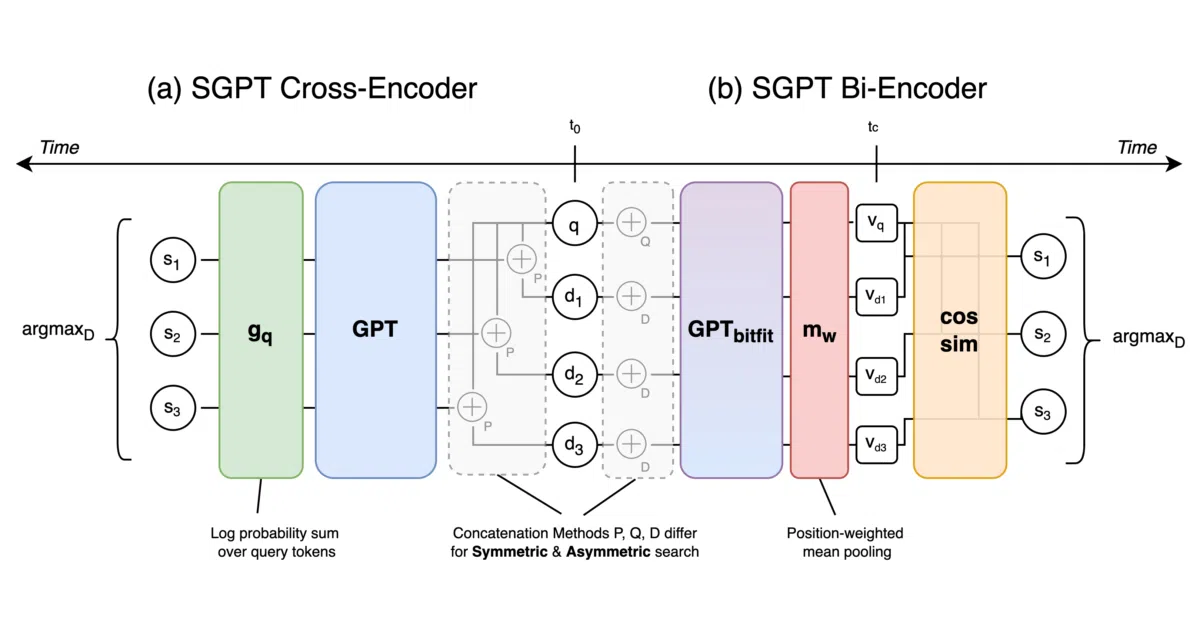
SGPT repurposes decoder-only GPT models for semantic search by fine-tuning only bias tensors and using position-weighted mean pooling.
Not currently ranked — collecting fresh signals.
star history
What it does SGPT turns GPT-style language models into sentence embedding engines for semantic search. It supports two modes: Bi-Encoders (independent query/document embeddings compared by cosine similarity) and Cross-Encoders (direct query-document scoring via log probabilities). Both symmetric and asymmetric search are supported, with asymmetric using special bracket tokens to distinguish queries from documents.
The interesting bit The Bi-Encoder approach is notably parsimonious: it fine-tunes only bias tensors via a “bitfit” approach and uses position-weighted mean pooling rather than a [CLS] token or simple averaging. The Cross-Encoder requires no fine-tuning at all—just log probabilities from the base GPT model. The authors also note their Cross-Encoder method is “very similar” to OpenAI’s Search Endpoint mechanism, which they discovered after publication.
Key highlights
- Bi-Encoders: contrastive fine-tuning of bias tensors only, with position-weighted mean pooling over hidden states
- Cross-Encoders: zero-fine-tuning approach using GPT log probabilities for query-document relevance scoring
- Asymmetric search uses special bracket tokens (
[ ]for queries,{ }for documents) to signal structure - Models from 125M to 5.8B parameters, plus multilingual BLOOM variants (1.7B and 7.1B)
- Integrates with both Hugging Face Transformers and Sentence Transformers
- Authors now recommend their successor GRIT & GritLM, which unifies bi-encoder, cross-encoder, and generation in one model
Caveats
- The repository is primarily research code and Jupyter notebooks; production robustness is unclear
- The authors themselves have moved on to GRIT/GritLM, suggesting SGPT is somewhat superseded
- The README examples require manual boilerplate for pooling and token manipulation; no clean one-liner API
Verdict Worth studying if you’re researching embedding methods or need to squeeze semantic search from existing GPT weights with minimal fine-tuning. Skip if you want a maintained, packaged solution—the authors point to GritLM instead, and modern embedding APIs have likely caught up.
Frequently asked
- What is Muennighoff/sgpt?
- SGPT repurposes decoder-only GPT models for semantic search by fine-tuning only bias tensors and using position-weighted mean pooling.
- Is sgpt open source?
- Yes — Muennighoff/sgpt is open source, released under the MIT license.
- What language is sgpt written in?
- Muennighoff/sgpt is primarily written in Jupyter Notebook.
- How popular is sgpt?
- Muennighoff/sgpt has 872 stars on GitHub.
- Where can I find sgpt?
- Muennighoff/sgpt is on GitHub at https://github.com/Muennighoff/sgpt.