MorvanZhou/pytorch-A3C
A3C in 200 lines: when PyTorch's multiprocessing beats TensorFlow
A stripped-down reference implementation showing why PyTorch's multiprocessing compatibility made it the pragmatic choice for asynchronous RL in 2018.
Not currently ranked — collecting fresh signals.
star history
What it does
Trains an A3C agent to balance a pole and swing up a pendulum using Python’s multiprocessing module, not threading. The repo contains two scripts—one for discrete actions (CartPole), one for continuous (Pendulum)—plus a shared Adam optimizer that synchronizes parameters across workers.
The interesting bit
The author explicitly built this because every other PyTorch A3C implementation was “too complicated to dig into.” The real insight is architectural: TensorFlow’s multiprocessing story was so broken that distributed TF was slower than threading on a single machine, while PyTorch’s torch.multiprocessing let the author skip the complexity entirely. It’s a case study in framework ergonomics masquerading as a toy RL example.
Key highlights
- Under 200 lines total, with separate discrete and continuous action implementations
- Uses actual multiprocessing (not threading), with a custom
SharedAdamoptimizer for parameter synchronization - Targets PyTorch ≥ 0.4.0—frozen in 2018, so expect API drift
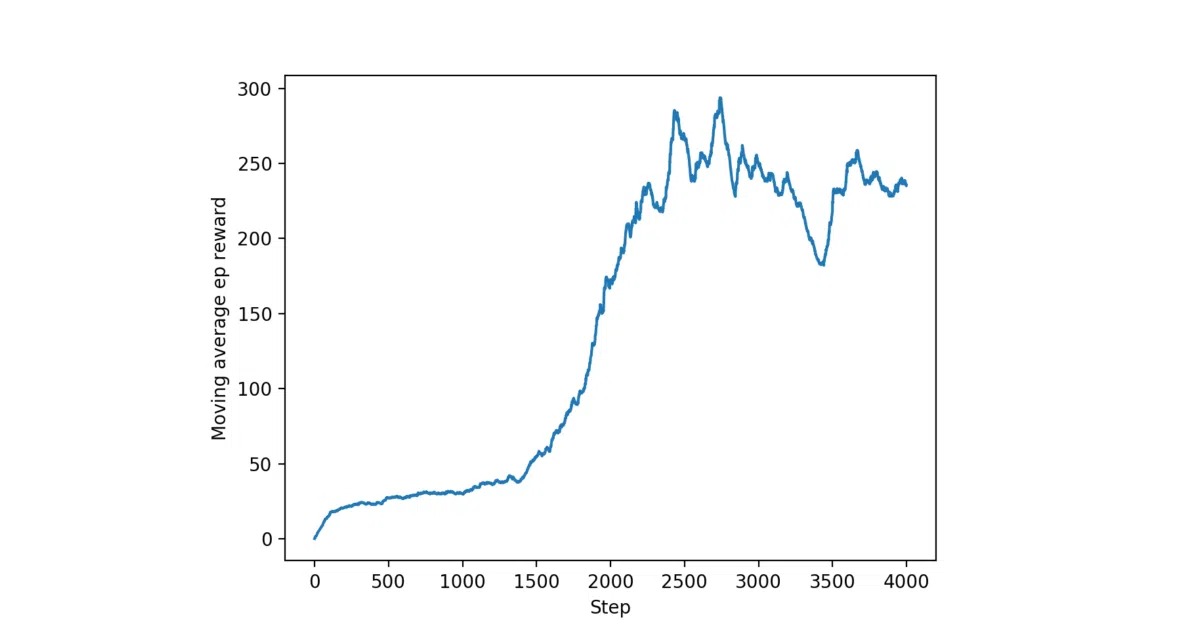
- Includes result plots for both environments
- Author’s explicit goal: “simplest toy implementation you can find” for learning the algorithm
Caveats
- PyTorch 0.4.0 is ancient; you’ll need to modernize tensor operations and possibly
multiprocessingcalls - Only tested on two classic control environments—don’t expect it to scale to Atari or MuJoCo without substantial work
- The “distributed TensorFlow” comparison is a single anecdote, not a benchmark
Verdict
Grab this if you’re teaching A3C or need to explain why PyTorch won the early RL ergonomics war. Skip it if you want production-ready distributed training or modern PyTorch patterns.
Frequently asked
- What is MorvanZhou/pytorch-A3C?
- A stripped-down reference implementation showing why PyTorch's multiprocessing compatibility made it the pragmatic choice for asynchronous RL in 2018.
- Is pytorch-A3C open source?
- Yes — MorvanZhou/pytorch-A3C is open source, released under the MIT license.
- What language is pytorch-A3C written in?
- MorvanZhou/pytorch-A3C is primarily written in Python.
- How popular is pytorch-A3C?
- MorvanZhou/pytorch-A3C has 659 stars on GitHub.
- Where can I find pytorch-A3C?
- MorvanZhou/pytorch-A3C is on GitHub at https://github.com/MorvanZhou/pytorch-A3C.