MoonshotAI/Moonlight
AdamW's new rival trains LLMs on half the compute
MoonshotAI open-sources a distributed Muon implementation and a 3B/16B MoE model that claims roughly 2× training efficiency over AdamW.
Not currently ranked — collecting fresh signals.
star history
What it does
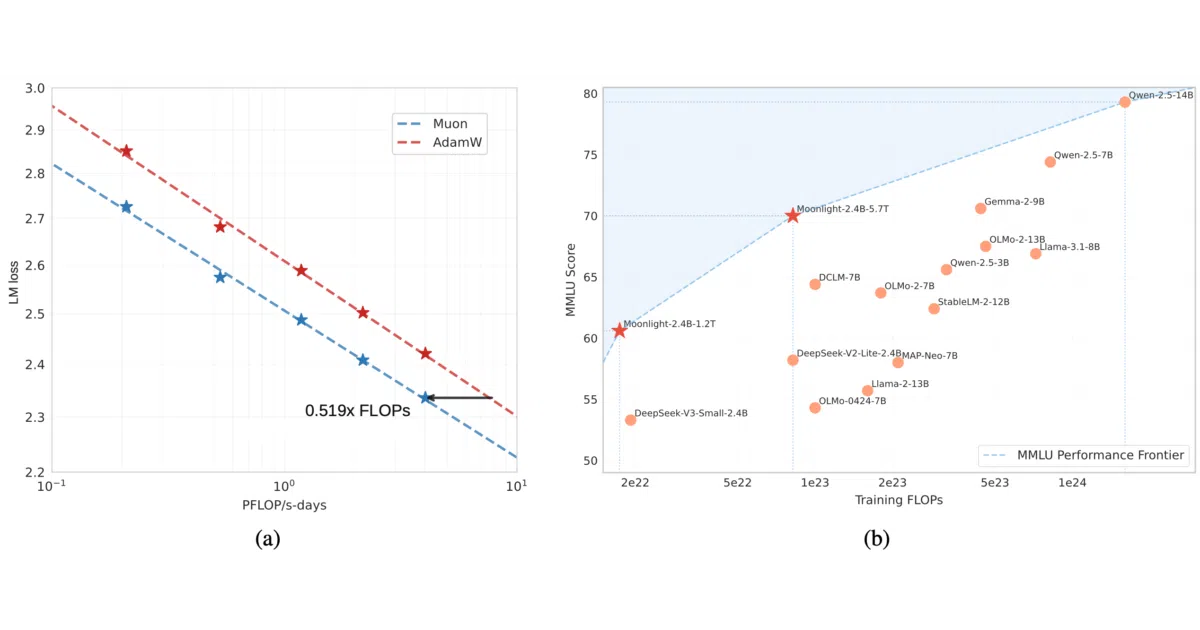
Moonlight is a 16B-parameter (3B active) Mixture-of-Experts language model built to prove that the Muon optimizer can scale beyond small experiments. MoonshotAI ships the pretrained and instruction-tuned weights, plus a distributed training implementation that uses ZeRO-1-style sharding to keep memory and communication costs down. The model shares DeepSeek-V3’s architecture, so it runs on standard inference engines like VLLM and SGLang.
The interesting bit
Muon relies on matrix orthogonalization, which worked for tiny models but used to fall apart at scale. The team stabilized it by adding weight decay and enforcing a consistent update RMS across both matrix and non-matrix parameters. Their scaling law plots suggest Muon matches AdamW’s quality while using about 52% of the training FLOPs.
Key highlights
- Benchmark table shows Moonlight leading Llama 3.2-3B, Qwen 2.5-3B, and DeepSeek-V2-Lite on MMLU, BBH, HumanEval, MBPP, MATH, and Chinese evaluations, despite training on only 5.7T tokens.
- The distributed Muon code preserves the algorithm’s mathematical properties while adding memory-optimal, communication-efficient sharding.
- Both pretrained and chat-tuned checkpoints are on HuggingFace, alongside a toy training script for smaller dense models.
- The repo notes the model advances the “Pareto frontier” of performance versus training FLOPs for its size class.
Caveats
- Intermediate checkpoints are listed as “coming soon,” so full training-curve analysis isn’t possible yet.
- Moonlight trails Qwen 2.5-3B on GSM8K (77.4 vs. 79.1), the one benchmark in the table where it doesn’t take the lead.
- The ~2× efficiency claim derives from the authors’ own scaling law experiments; independent reproduction isn’t discussed.
Verdict
Training engineers looking to squeeze more performance from limited compute should study this closely; it’s a rare case where the optimizer itself is the main event. Casual users just need another competent small MoE to chat with, though the 8K context limit is fairly standard.
Frequently asked
- What is MoonshotAI/Moonlight?
- MoonshotAI open-sources a distributed Muon implementation and a 3B/16B MoE model that claims roughly 2× training efficiency over AdamW.
- Is Moonlight open source?
- Yes — MoonshotAI/Moonlight is open source, released under the MIT license.
- How popular is Moonlight?
- MoonshotAI/Moonlight has 1.5k stars on GitHub.
- Where can I find Moonlight?
- MoonshotAI/Moonlight is on GitHub at https://github.com/MoonshotAI/Moonlight.