MoonshotAI/Kimi-K2
A trillion-parameter model that only wakes up 3% of its brain
Moonshot AI's Kimi K2 uses sparse activation to deliver frontier coding and agentic performance without the usual training fireworks.
Not currently ranked — collecting fresh signals.
star history
What it does
Kimi K2 is a 1-trillion-parameter mixture-of-experts (MoE) language model that activates only 32 billion parameters per token. It comes in two flavors: a base model for researchers who want to fine-tune, and an instruct-tuned variant optimized for tool use, coding, and autonomous problem-solving. The model supports 128K context and uses Multi-Head Latent Attention (MLA) rather than standard attention.
The interesting bit
The team trained this 1T-parameter beast on 15.5T tokens with what they claim is “zero training instability” — a notable claim given the usual fireworks when scaling MoEs. The trick is a modified Muon optimizer (dubbed MuonClip) that apparently tames the chaos at unprecedented scale. It’s also designed as a “reflex-grade” model, meaning it aims to act without the long chain-of-thought pauses that characterize reasoning-specialist models.
Key highlights
- 1T total parameters, 32B activated, 384 experts with 8 selected per token
- Pre-trained on 15.5T tokens using a modified Muon optimizer
- Two variants: Kimi-K2-Base (for fine-tuning) and Kimi-K2-Instruct (drop-in chat/agentic use)
- 128K context window, 160K vocabulary, SwiGLU activation
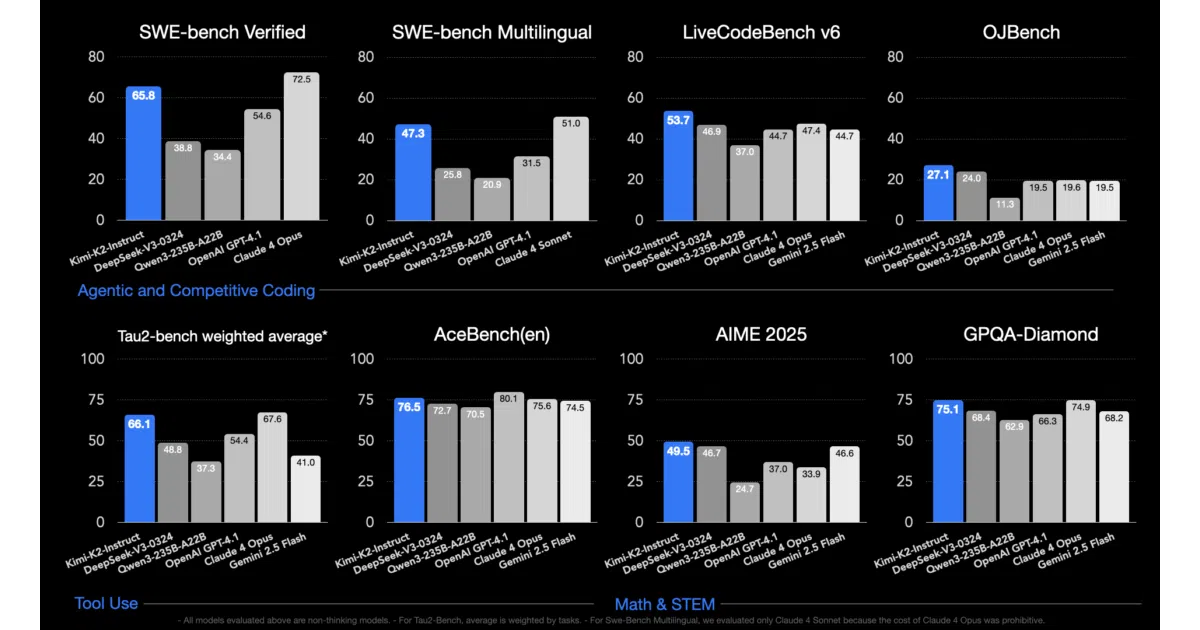
- Benchmark tables show competitive or leading scores on LiveCodeBench, SWE-bench, and several math/STEM tasks against DeepSeek-V3, Claude Opus 4, GPT-4.1, and Gemini 2.5 Flash
- Released under a Modified MIT license
Caveats
- The README is essentially a model card with benchmark tables; no code, inference scripts, or deployment guides are included in the repository
- “Zero training instability” and MuonClip details are claimed but not substantiated with technical depth in the README (the full report is on arXiv)
- Some benchmark comparisons use different evaluation settings (noted with asterisks), making direct comparison tricky
Verdict
Worth tracking if you’re building agentic systems or researching MoE training stability — the sparse activation efficiency is genuinely interesting. Skip if you’re looking for a ready-to-run open-source implementation; this repo is documentation and weights, not a framework.
Frequently asked
- What is MoonshotAI/Kimi-K2?
- Moonshot AI's Kimi K2 uses sparse activation to deliver frontier coding and agentic performance without the usual training fireworks.
- Is Kimi-K2 open source?
- Yes — MoonshotAI/Kimi-K2 is an open-source project tracked on heatdrop.
- How popular is Kimi-K2?
- MoonshotAI/Kimi-K2 has 10.9k stars on GitHub.
- Where can I find Kimi-K2?
- MoonshotAI/Kimi-K2 is on GitHub at https://github.com/MoonshotAI/Kimi-K2.