MiroMindAI/MiroThinker
An open-source research agent that learned to Google harder, not just bigger
MiroThinker treats "number of tool calls" as a trainable dimension of intelligence, letting a 30B model punch above its weight on deep research benchmarks.
Not currently ranked — collecting fresh signals.
star history
What it does MiroThinker is a family of open-source deep-research agents built on Qwen3 base models. They browse, search, and reason across hundreds of steps to answer complex questions. The project ships models at 30B and 235B parameters, plus a proprietary H1 variant, all trained specifically for long-horizon tool-augmented reasoning rather than simple chat completion.
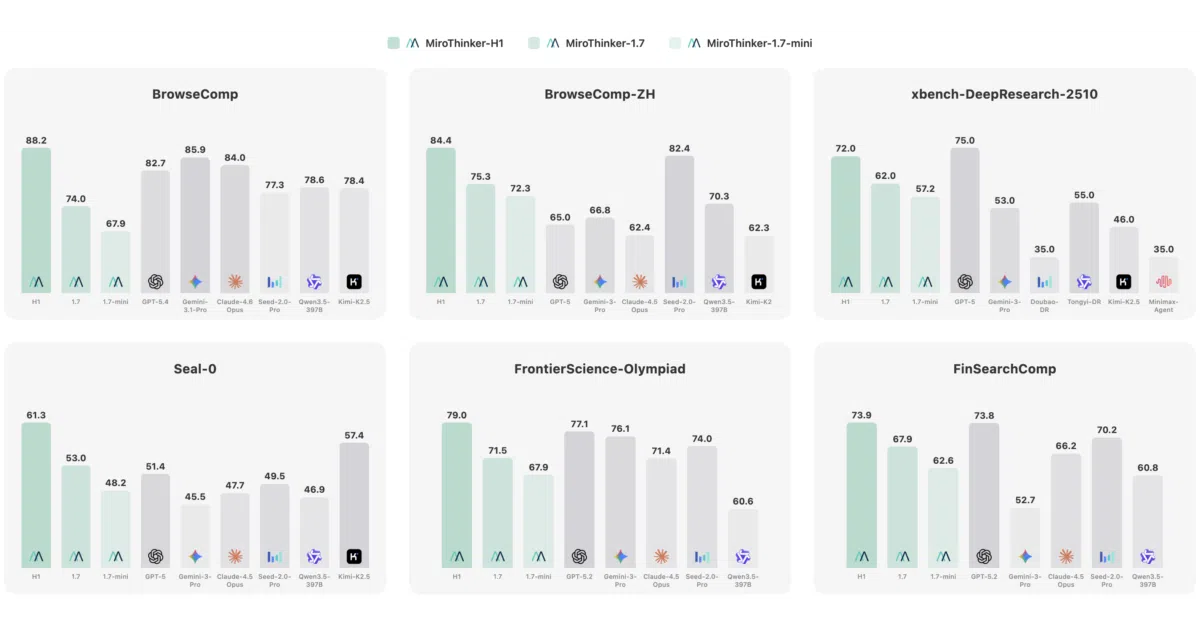
The interesting bit The team calls it “interactive scaling” — treating how often an agent talks to its tools as a third lever alongside model size and context length. Version 1.0 pushed this to 600 tool calls per task; 1.7 has refined it to 300 interactions with what they claim is more accurate stepwise decision-making. The 30B “mini” model hits 72.3% on BrowseComp-ZH, which the README explicitly flags as open-source SOTA at that parameter count.
Key highlights
- 256K context window across all recent versions
- Benchmark claims: 74.0% BrowseComp, 75.3% BrowseComp-ZH, 82.7% GAIA-Val-165 for the 235B 1.7 model
- 30B mini model reportedly beats Kimi-K2-Thinking on BrowseComp-ZH using 1/30 the parameters
- Proprietary MiroThinker-H1 mentioned as “leading performance among open-source and commercial models” — no specific numbers provided
- Live demo at dr.miromind.ai with PDF/Office document upload support
Caveats
- The README’s top banner claims “88.2 on BrowseComp” but the detailed 1.7 section lists 74.0%; the 88.2 figure is unattributed and may refer to the proprietary H1 agent
- “SOTA” claims are frequent but benchmark coverage is narrow — heavy focus on BrowseComp variants and GAIA with limited comparison points
- Training data and exact post-training pipeline details are vague beyond “enhanced”
Verdict Worth watching if you’re building research agents or need a local alternative to commercial deep-research tools. Skip if you need transparent reproducibility of the top-line 88.2% claim or if your use case doesn’t involve multi-step web search.
Frequently asked
- What is MiroMindAI/MiroThinker?
- MiroThinker treats "number of tool calls" as a trainable dimension of intelligence, letting a 30B model punch above its weight on deep research benchmarks.
- Is MiroThinker open source?
- Yes — MiroMindAI/MiroThinker is open source, released under the Apache-2.0 license.
- What language is MiroThinker written in?
- MiroMindAI/MiroThinker is primarily written in Python.
- How popular is MiroThinker?
- MiroMindAI/MiroThinker has 8.3k stars on GitHub.
- Where can I find MiroThinker?
- MiroMindAI/MiroThinker is on GitHub at https://github.com/MiroMindAI/MiroThinker.