MinishLab/semble
Semantic code search that keeps agents off the token treadmill
Semble exists so agents can find code by intent instead of grepping entire files and hauling them into context.
Velocity · 7d
+8.7
★ / day
Trend
↘cooling
star history
What it does
Semble indexes a codebase locally on CPU and answers natural-language queries with the exact code snippets an agent needs. It replaces the usual agent workflow of grepping for hints and pulling entire files into the prompt. The index builds in about 250 ms for an average repo and persists across sessions, invalidating itself automatically when files change.
The interesting bit
Instead of shipping context-heavy transformer models to the GPU, Semble claims to hit 99% of their retrieval quality with ~200× faster indexing and ~10× faster queries, all while staying entirely offline. It exposes this through an MCP server, an AGENTS.md snippet, or a dedicated sub-agent, effectively turning “find the auth logic” into a native tool call.
Key highlights
- Returns only relevant chunks, claiming ~98% fewer tokens than grep-and-read workflows.
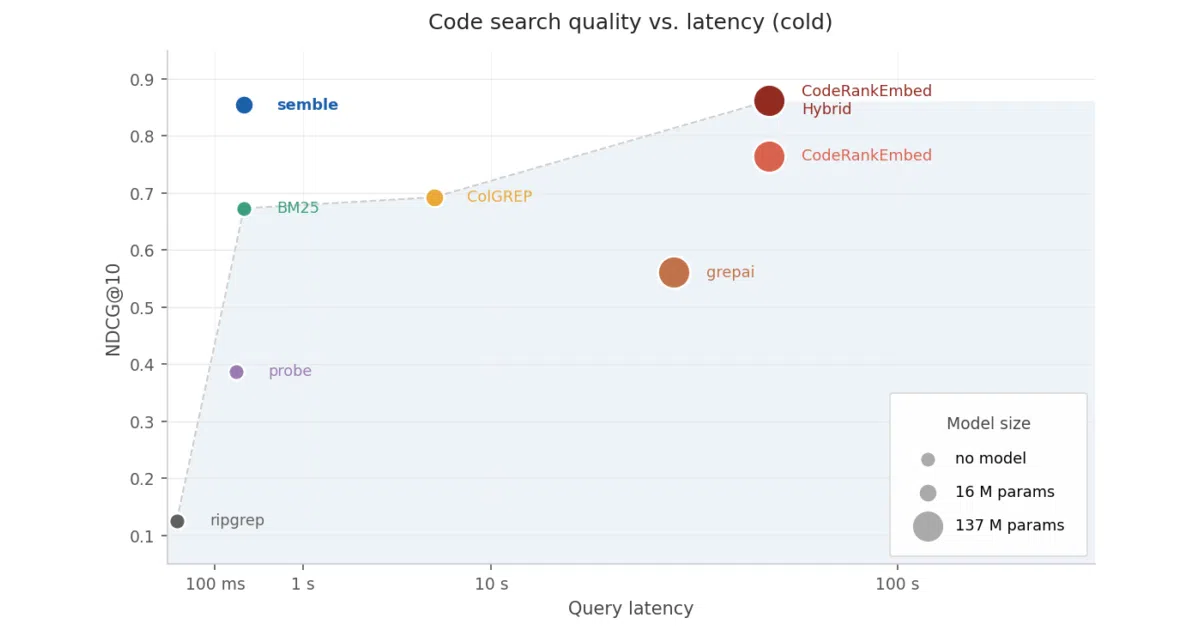
- NDCG@10 of 0.854 on its own benchmarks, roughly on par with code-specific transformer models.
- Runs fully offline on CPU: no API keys, GPU, or external services.
- Supports local directories and git URLs, with automatic caching and re-indexing on file changes.
- Can search code, documentation, or config via
--contentflags, and offers afind-relatedtool for jumping from a known line to similar implementations.
Verdict
Worth a look if you are wiring up Claude Code, Cursor, or another MCP-compatible agent and want to stop paying context-window rent on every repo. Less useful if your workflow already lives entirely inside an IDE with built-in semantic search.
Frequently asked
- What is MinishLab/semble?
- Semble exists so agents can find code by intent instead of grepping entire files and hauling them into context.
- Is semble open source?
- Yes — MinishLab/semble is open source, released under the MIT license.
- What language is semble written in?
- MinishLab/semble is primarily written in Python.
- How popular is semble?
- MinishLab/semble has 5.7k stars on GitHub and is currently cooling off.
- Where can I find semble?
- MinishLab/semble is on GitHub at https://github.com/MinishLab/semble.