Mesh-LLM/mesh-llm
Pool Disparate GPUs Into a Single OpenAI-Compatible Inference Mesh
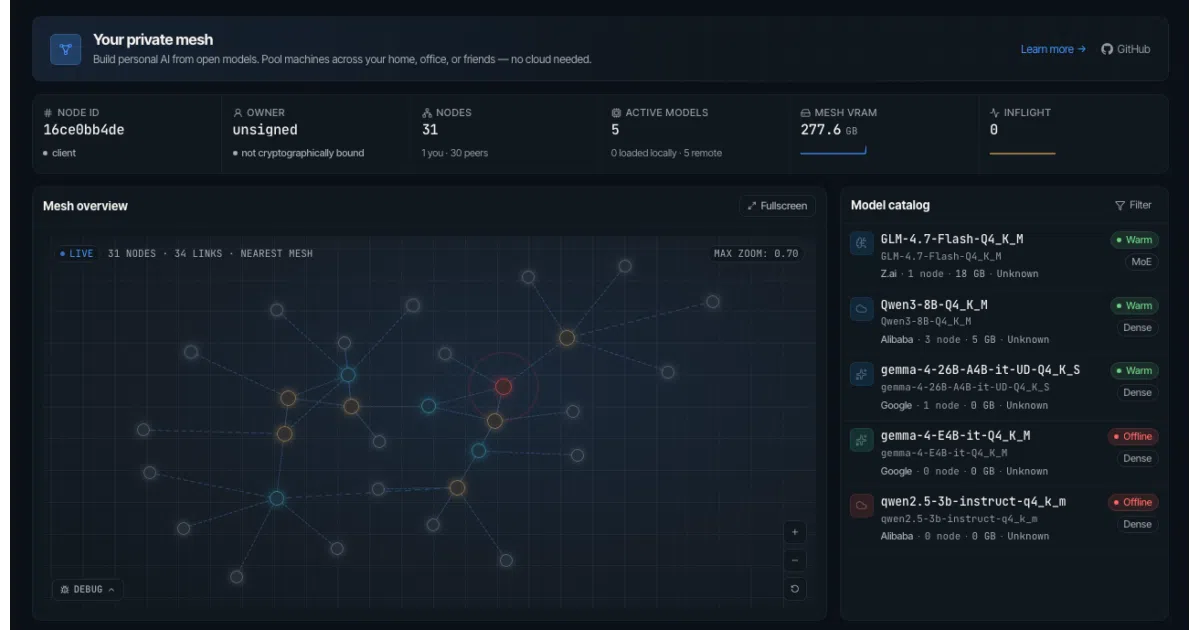
Mesh LLM lets you pool GPUs and memory across machines into a single OpenAI-compatible API, routing requests locally, to peers, or across package-backed layer stages for models too large to fit on one box.
Velocity · 7d
+45
★ / day
Trend
↘cooling
star history
What it does
Mesh LLM is a Rust-based distributed inference layer. Start a node on one machine, add more later, and the cluster presents itself as a single OpenAI-compatible API at localhost:9337/v1. The mesh decides whether to run a model locally, route the request to a peer that has it loaded, or shard a too-large model across multiple boxes using its Skippy stage-splitting system.
The interesting bit
The Skippy runtime breaks massive dense models into package-backed layer stages distributed across the mesh, so peers fetch only the specific GGUF fragments they need rather than the whole weights file. There is also an experimental Mixture-of-Agents gateway: send a request with model: "mesh" and it fans the prompt out to every distinct model in the cluster in parallel, arbitrates the answers with deterministic code, and returns a single consensus response—escalating to a reducer LLM only if the answers genuinely disagree.
Key highlights
- Every node exposes the same
/v1API; routing happens automatically by model ID. - Public meshes advertise via Nostr discovery; private meshes lock down with invite tokens.
- Supports a wide catalog of GGUF families—89 certified rows tracking llama.cpp parity, including Qwen, Llama, DeepSeek, Gemma, Mistral, and others.
- Split multimodal serving is certified for several vision models, with heavyweights like DeepSeek3 and EXAONE-MoE handled via package-backed stages.
- Ships with broad backend support—CUDA, ROCm, Vulkan, Metal, and CPU—across macOS, Linux, and Windows.
Caveats
- The project labels itself “experimental distributed-systems software,” and the Mixture-of-Agents gateway is explicitly flagged as a preview feature with heuristics and error shapes that may shift between releases.
- Embedded release attestation is for provenance hardening only; the README notes it is not a runtime integrity proof, and default startup still allows binaries that fail attestation checks.
Verdict
Worth a look if you have multiple machines with GPUs sitting idle and want to treat them as one elastic inference backend. Probably overkill if you are just serving a single 7B model on one GPU.
Frequently asked
- What is Mesh-LLM/mesh-llm?
- Mesh LLM lets you pool GPUs and memory across machines into a single OpenAI-compatible API, routing requests locally, to peers, or across package-backed layer stages for models too large to fit on one box.
- Is mesh-llm open source?
- Yes — Mesh-LLM/mesh-llm is open source, released under the Apache-2.0 license.
- What language is mesh-llm written in?
- Mesh-LLM/mesh-llm is primarily written in Rust.
- How popular is mesh-llm?
- Mesh-LLM/mesh-llm has 2.8k stars on GitHub and is currently cooling off.
- Where can I find mesh-llm?
- Mesh-LLM/mesh-llm is on GitHub at https://github.com/Mesh-LLM/mesh-llm.